Project: Suppliers
Compile Digger
Do you want to run the web scrapers on your computer without any connection to Diggernaut service? Then this feature is for you! :)
With the unique opportunity provided by our service, you can compile your digger into an independent executable file for the platform you need. This opportunity allows, in some cases, to significantly save resources, but imposes certain restrictions: if you need to run a digger on a schedule, then you will need to organize it on your side yourself using scheduler your OS provides you with; The compiled digger can not use the export templates and data validation schema; you will not be able to work with such digger via Diggernaut API; it doesnt support "update mode" for data scraping; digger will not be able to use OCR functionality and other Diggernaut services.
To switch to the compilation mode, press the Options button.

and let's take a closer look at all available options.
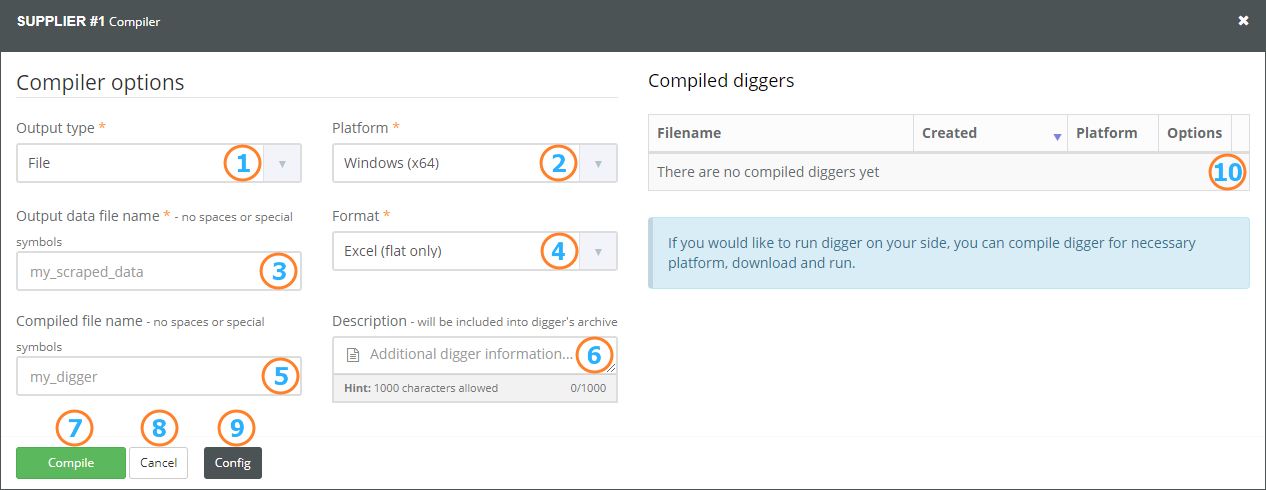
- Data output type
- Execution platform
- Filename (with output type File)
- Data format (with output type File)
- The filename for the compiled digger / archive (optional)
- Additional description (optional)
- Compile
- Close compilation panel
- Digger configuration
- List of compiled diggers
Saving data to the file
Data output type - defines where digger will output scraped data. Right now Diggernaut supports 3 different options:
File - data will be written to the file.
Database (SQL) - data will be written to the SQL database.
STDOUT - data will be written to the standard output channel of the OS.
Platform - defines a platform for which the executable digger will be compiled. Diggernaut supports Windows, MacOS and Linux operating systems, both 32-bit and 64-bit.
Filename - filename for the file where scraped data will be written to.. The file name must be specified without spaces, without using special characters and without an extension (the extension will be given to the file automatically, depending on the data format selected). This field is available only when the File output type is selected.
Data format - let you to select one of the following options: Excel (only flat data structures), CSV (only flat data structures),
JSON and XML.
This field is available only when the File output type is selected.
The differences in formats were described in the Scraped Data section.
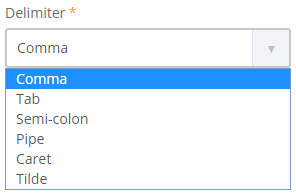
If you select CSV (flat only) option, another setting will be available - Delimiter, where you can select the character that
will be used as data fields separator.
Filename for compiled digger/archive - filename without an extension, which will be assigned to the compiled digger, as well as the archive where the diger executable file will be placed along with the additional files. If this field is not filled, the system will assign the name automatically.
Additional description - The value of this field will be included to the compilation options file diggername_options.txt, which will be included to the archive with executable. In this field it is useful to save information about what and where from this scraper gets data. That will allow quickly to understand purpose of the scraper in the future :)
Compile buttons starts compilation process. You cannot compile more than 1 digger per minute.
When compilation is done, you will see dowloadable archive in the list of the compiled diggers,
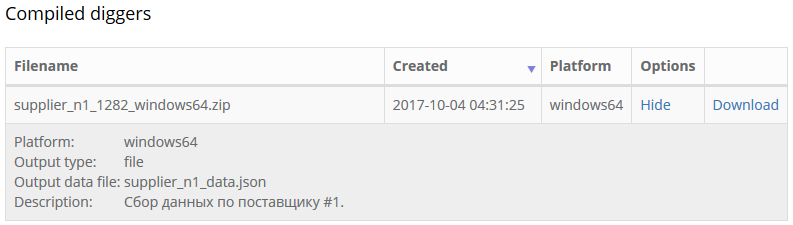 which will contain the following files:
which will contain the following files:
supplier_n1_1282_windows64.exe - executable scraper file with .exe extension for the windows x64 platform;
supplier_n1_1282_options.txt - help file with start-up options, and additional description data;
supplier_n1_1282_config.yaml - digger configuration in YAML format;
howto-compile-en.txt - short manual, describing compilation process and possible options, in english;
howto-compile-ru.txt - short manual, describing compilation process and possible options, in russian;
To run the scraper on your computer, you need to unpack the archive and run the executable. While the scraper is working, in addition to the file with data, there is a log file will be created. Scraper will write the progress of the scraping process to this log file. You can use this file to control the execution. Also if you have any questions, you can attach this file when communicating with a Diggernaut customer support. The scraper will also display the progress of the scraping process to the console, in all cases except when the selected data output type is STDOUT. In this case, the data will be shown in the console, and the progress of the scraping process will only be available in the log file.
Please note:
At any time, you can interrupt the execution of the digger by pressing Ctrl + C or Command (⌘) - Q. In this case, if the digger has already collected some data, it will be saved to the data file of the choosen format. This is true for all formats except Excel (flat only). Excel file (XLSX) is written at the very end of digger job, so interrupting execution will cause losing scraped data.
Save to the database
If you change the data output type to the Database (SQL), some options will be changed to the settings for accessing the database.
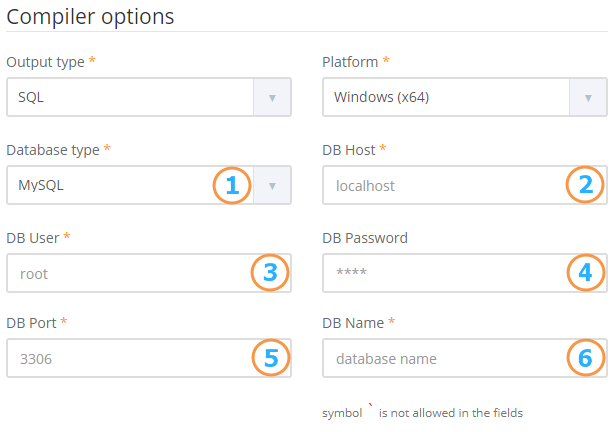
- Database type, can select one of: MySQL, PostgreSQL, MicrosoftSQL
- Hostname of database server
- Username to access DB
- Password to access DB (optional)
- Port of DB server
- Database name
Please note:
The use of the ` character is not allowed in the fields.
Save to STDOUT
If you select STDOUT, digger will write scraped data to the console. In this case, progress of the scraping process can be tracked in the log file. The data format can be selected in the additional field.
Allowed data formats: CSV (only flat), JSON and XML.
Next