In this article, we will teach you how generally you can scrape the data from the websites with infinite scroll and build the Instagram scraper. All you will need to do it is just your browser, a free account on the Diggernaut platform, and your head and hands.
Updated on 01.10.2020
Infinite scroll on the webpage is based on Javascript functionality. Therefore, to find out what URL we need to access and what parameters to use, we need to either thoroughly study the JS code that works on the page or, and preferably, examine the requests that the browser does when you scroll down the page. We can study requests using the Developer Tools, which are built-in to all modern browsers. In this article, we are going to use Google Chrome, but you can use any other browser. Just keep in mind that the developer tools may look different in different browsers.
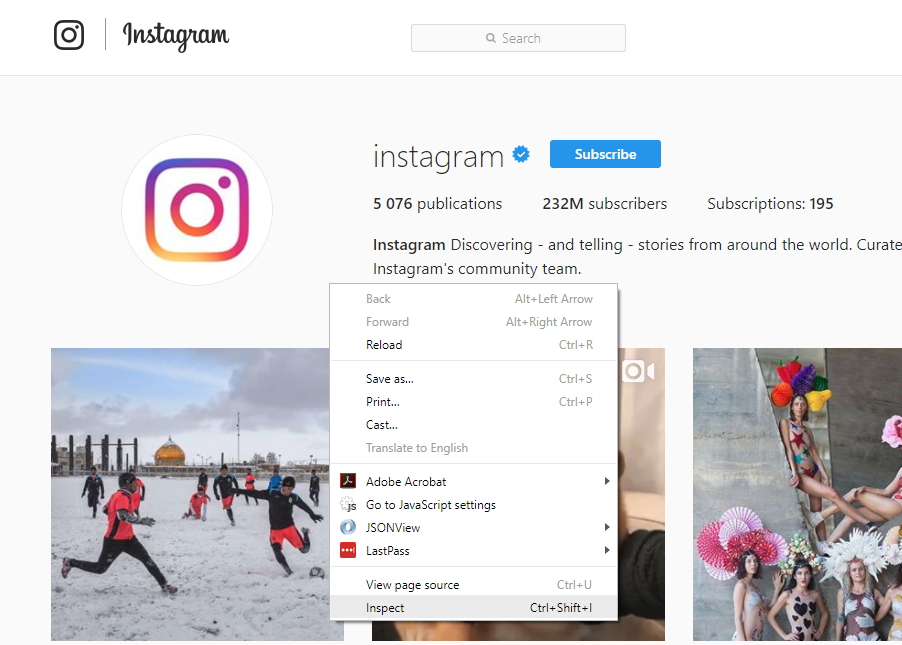
We will use an official Instagram channel. Open this page in the browser, and run Chrome Dev Tools – developer tools that are built-in to Google Chrome. To do it, you need to right-click anywhere on the page and select the “Inspect” option or press “Ctrl + Shift + I”:
{kind=link}
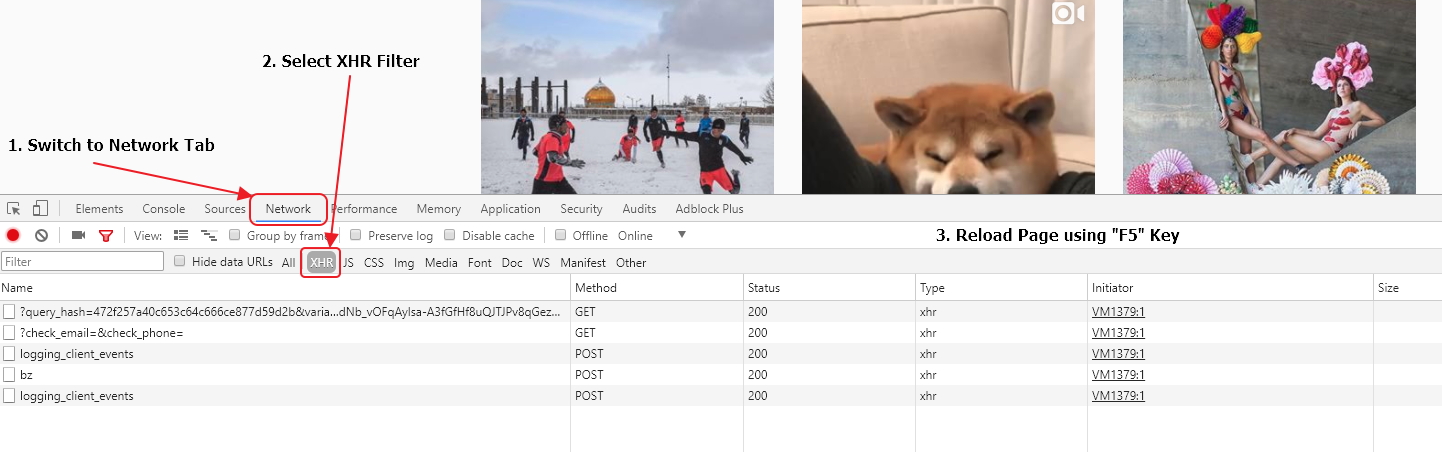
It will open the tool window, where we go to the Network tab, and in the filters, we select only XHR requests. We do it to filter out requests we don’t need. After that, reload the page in the browser using the Reload button in the browser interface or the “F5” key on the keyboard.
{kind=link}
Let’s now scroll down the page several times with the mouse wheel. It will cause content loading. Whenever we scroll down to the bottom of the page, JS makes an XHR request to the server, receive the data and add it to the page. As a result, we should have several requests in the list that look almost the same. Most likely its what we are looking for.
{kind=link}
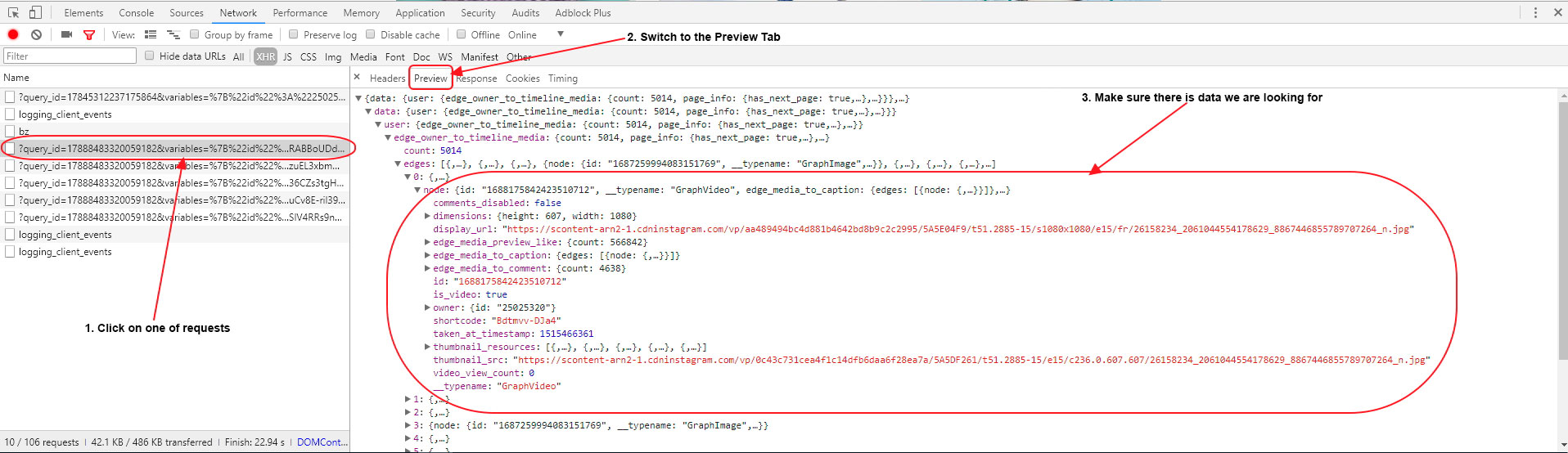
To make sure, we have to click on one of the requests and in the newly opened panel go to the Preview tab. There we can see the formatted content that the server returns to the browser for this request. Let’s get to one of the leaf elements in the tree and make sure that there are data about the images that we have on the page.
{kind=link}
After making sure that these are the queries we need, let’s look at one of them more carefully. To do it, go to the Headers tab. There, we can find information about what URL is used to make the request, what is the type of that request (POST or GET), and what parameters are passed with the request.
{kind=link}
It’s better to check query string parameters at Query String Parameters section. To see it, you need to scroll down the pane to the bottom:
{kind=link}
As result of our analysis we get the following:
Request URL: https://www.instagram.com/graphql/query/
Request type: GET
Query string parameters: query_hash and variables
Obviously, some static id is passed as query_hash, which is generated by JS or exist either on the page, cookie or some JS file. There are also some parameters, which defines what exactly you get from the server are passed in the JSON format as the variables query parameter.
Now we need to understand where query_hash comes from. If we go to the Elements tab and try to find (CTRL + F) our query_hash e769aa130647d2354c40ea6a439bfc08, then we find out that it doesn’t exist on the page itself, which means that it is loaded or generated somewhere in the Javascript code, or comes with cookies. Therefore, go back to the Network tab and put the filter on JS. Thus, we can see only requests for JS files. Sequentially browsing the request by request, we have to search for our id in the loaded JS files: just click on the request, then open the Response tab in the opened panel to see the content of JS and do a search for our id (CTRL + F). After several unsuccessful attempts, we find that our id is in the following JS file:
https://www.instagram.com/static/bundles/ProfilePageContainer.js/031ac4860b53.js
and the code fragment that surrounds the id looks like this:
profilePosts.byUserId.get(n))||void 0===s?void 0:s.pagination},queryId:"e769aa130647d2354c40ea6a439bfc08",queryParams
So, to get query_hash, we need to:
- Load main channel page
- Find the URL to the file which filename contains ProfilePageContainer.js
- Extract this URL
- Load JS file
- Parse the id we need
- Write it into a variable for later use.
Now let’s see what data is passed as variables parameter:
{"id":"25025320","first":12,"after":"AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A"}
If we analyze all XHR requests that load data, we find that only the after parameter changes. Therefore id most likely is the id of the channel, which we need to extract from somewhere, first – the number of records that the server should return, and after is the id of the last record shown.
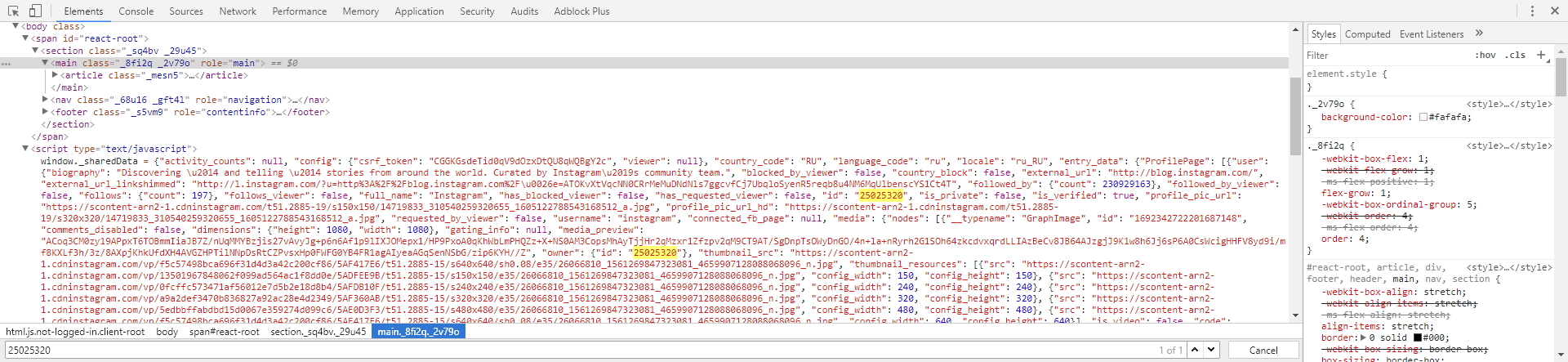
We need to find where we can extract the channel id. So the first thing we do is look for the text 25025320 in the source code of the main channel page. Let’s go to the Elements tab and do a search (CTRL + F) for our id. We find that it exists in the JSON structure on the page itself, and we can easily extract it:
{kind=link}
It seems everything is clear, but where do we get after value for each subsequent data loading? It is straightforward. Since it gets changed with each new loading, it’s most likely loaded with the data feed. Let’s look at the loaded data again more carefully:
We will see the following data structure there:
data: {
user: {
edge_owner_to_timeline_media: {
count: 5014,
page_info: {
has_next_page: true,
end_cursor: "AQCCoEpYvQtj0-NgbaQUg9g4ffOJf8drV2RieFJw1RA3E9lDoc8euxXjeuwlUEtXB6CRS9Zs2ZGJcNKseKF9f6b0cN0VC3ck8rnTfOw5q8nlJw"
}
}
}
}
where end_cursor looks like what we are looking for. Also, there is field has_next_page which can be very handy for us so we could stop loading feeds with data if there is no more data available.
Now we’ll write the beginning part of our Instagram scraper, load the main channel page and try to load the JS file with query_hash. Create a digger in your Diggernaut account and add the following configuration to it:
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:Set the Digger to the Debug mode. Now we need to run our Instagram scraper, and when the job is done, we are going to check the log. At the end of the log, we can see how the diggernaut works with JS files. It converts them into the following structure:
So the CSS selector for all JS script content will be script. Let’s add the query_hash parsing function:
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryidLet’s save our digger configuration and rerun it. Wait until it finishes the job and recheck the log. In the log we see the following line:
Set variable queryid to register value: df16f80848b2de5a3ca9495d781f98df
It means that query_hash was successfully extracted and written to the variable named queryid.
Now we need to extract the channel id. As you remember, it is in the JSON object on the page itself. So we need to parse the contents of a specific script element, pull JSON out of there, convert it to XML, and take the value we need using the CSS selector.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
# Parse only JSON content
- parse:
filter: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chidIf you look closely at the log, you can see that the JSON structure is transformed into an XML DOM like this:
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
It helps us build CSS selectors to get the first 12 records and the last record marker which we are going to use in after parameter for the request we send to the server to get next 12 records. Let’s write the logic for data extraction, and also let’s use a pool of links. We are going to iterate links in this pool and consequently add next page URL to this pool. Once next 12 records are loaded we are going to stop and see how loaded JSON is transformed to XML so we could build CSS selectors for data we want to extract.
Most recently, Instagram made changes to the public API. Now authorization is done not by using CSRF token, but by a particular signature, which is calculated with the new parameter rhx_gis, passed in the sharedData object on the page. You can learn used algorithm if you research JS of Instagram. Mainly its just MD5 sum of some parameters joined to a single string. So we use this algorithm and automatically sign requests. To do it, we need to extract the rhx_gis parameter.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# extracting JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
- exit
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chid
# Find elements where rhx_gis is kept
- find:
path: rhx_gis
do:
# Parse content of the current block
- parse
# Set parsed value to the variable rhxgis
- variable_set: rhxgis
# Find record elements and iterate over them
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Create new object named item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Find element where next page data kept
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page
- find:
path: has_next_page
do:
# parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read variable hnp to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, then find element with last shown record marker
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable with name cursor
- variable_set: cursor
# Apply URL-encode for the value (since it may contain characters not allowed in the URL)
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable with name cursor
- variable_set: cursor_encoded
# Form pool of links and add first link to this pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Set counter for number of loads to 0
- counter_set:
name: pages
value: 0
# Iterate over the pool and load current URL using signature in request header
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:Again, save the configuration and run the digger. Wait for completion and check the log. You should see the following structure for loaded JSON with next 12 records:
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
We shortened source code on purpose. We just removed all records from data except the first record. Since the structure is the same for all records, we need to see the structure of one record to build CSS selectors. Now we can define the logic of scraping for all fields we need. We are going to set the limit to the number of loads also, let’s say to 10. Moreover, add a pause for less aggressive scraping. As a result, we get the final version of our Instagram scraper.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# extracting JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chid
# Find elements where rhx_gis is kept
- find:
path: rhx_gis
do:
# Parse content of the current block
- parse
# Set parsed value to the variable rhxgis
- variable_set: rhxgis
# Find record elements and iterate over them
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Create new object named item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Find element where next page data kept
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page
- find:
path: has_next_page
do:
# parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read variable hnp to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, then find element with last shown record marker
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable with name cursor
- variable_set: cursor
# Apply URL-encode for the value (since it may contain characters not allowed in the URL)
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable with name cursor
- variable_set: cursor_encoded
# Form pool of links and add first link to this pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Set counter for number of loads to 0
- counter_set:
name: pages
value: 0
# Iterate over the pool and load current URL using signature in request header
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Find element that hold data used for loading next page
- find:
path: edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page available
- find:
path: has_next_page
do:
# Parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read the variable to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, check loads counter if its greater than 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# If not, find element with the cursor
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable
- variable_set: cursor
# Doing URL-encode
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable
- variable_set: cursor_encoded
# Add next page URL to the links pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Find record elements and iterate over them
- find:
path: edge_owner_to_timeline_media > edges > node
do:
# Create object with name item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Increment loads counter by 1
- counter_increment:
name: pages
by: 1We hope that this article helps you to learn the meta-language and now you can solve tasks where you need to parse pages with infinite scroll without problems.
Happy Scraping!