
In this article, we will teach you how generally you can scrape the data from the websites with infinite scroll and build the Instagram scraper. All you will need to do it is just your browser, a free account on the Diggernaut platform, and your head and hands.
Updated on 01.10.2020
Infinite scroll on the webpage is based on Javascript functionality. Therefore, to find out what URL we need to access and what parameters to use, we need to either thoroughly study the JS code that works on the page or, and preferably, examine the requests that the browser does when you scroll down the page. We can study requests using the Developer Tools, which are built-in to all modern browsers. In this article, we are going to use Google Chrome, but you can use any other browser. Just keep in mind that the developer tools may look different in different browsers.
We will use an official Instagram channel. Open this page in the browser, and run Chrome Dev Tools – developer tools that are built-in to Google Chrome. To do it, you need to right-click anywhere on the page and select the “Inspect” option or press “Ctrl + Shift + I”:
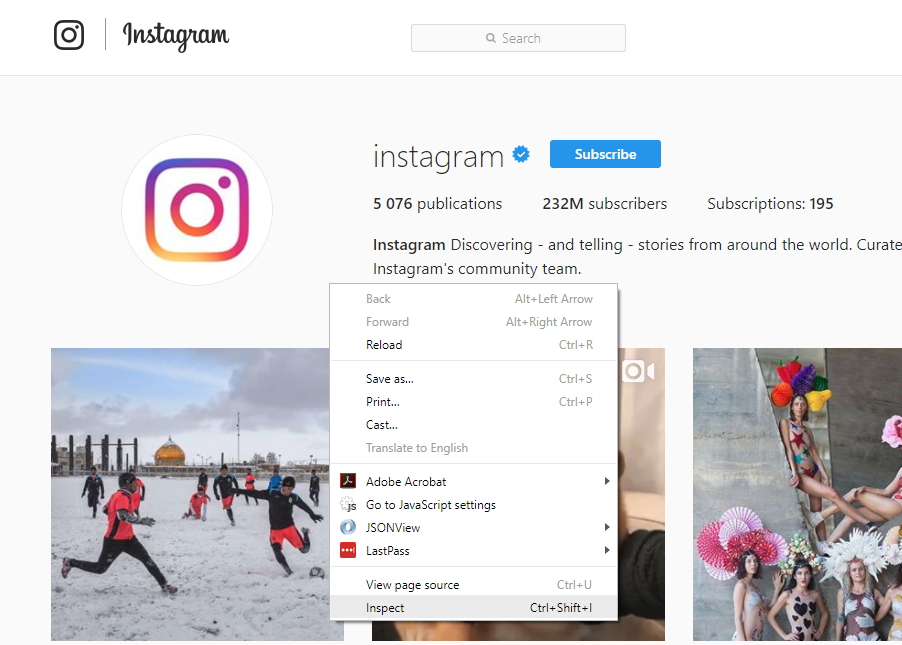
It will open the tool window, where we go to the Network tab, and in the filters, we select only XHR requests. We do it to filter out requests we don’t need. After that, reload the page in the browser using the Reload button in the browser interface or the “F5” key on the keyboard.
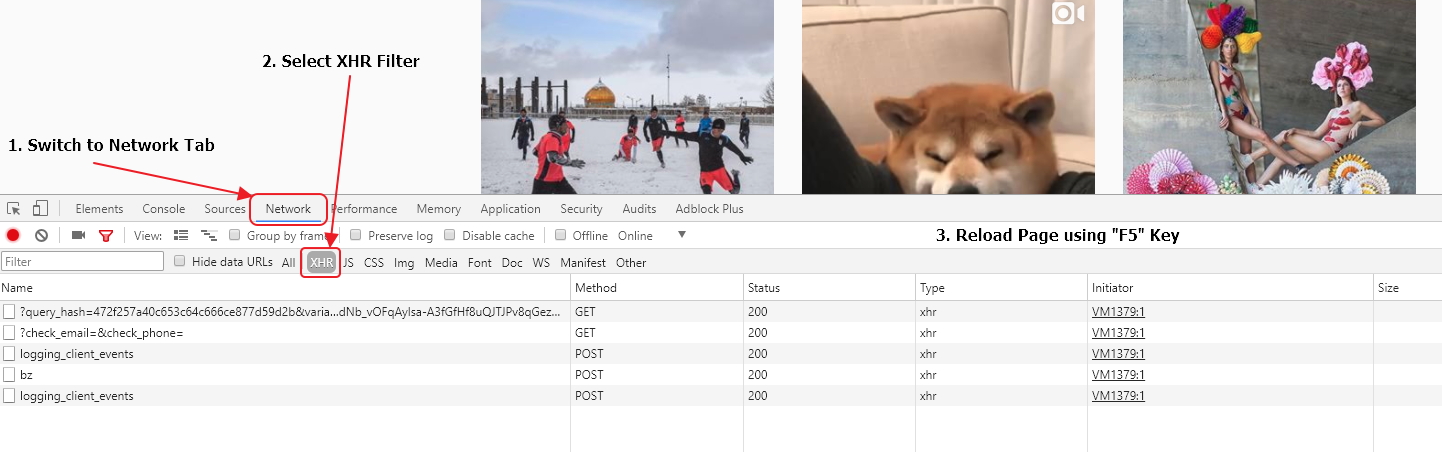
Let’s now scroll down the page several times with the mouse wheel. It will cause content loading. Whenever we scroll down to the bottom of the page, JS makes an XHR request to the server, receive the data and add it to the page. As a result, we should have several requests in the list that look almost the same. Most likely its what we are looking for.

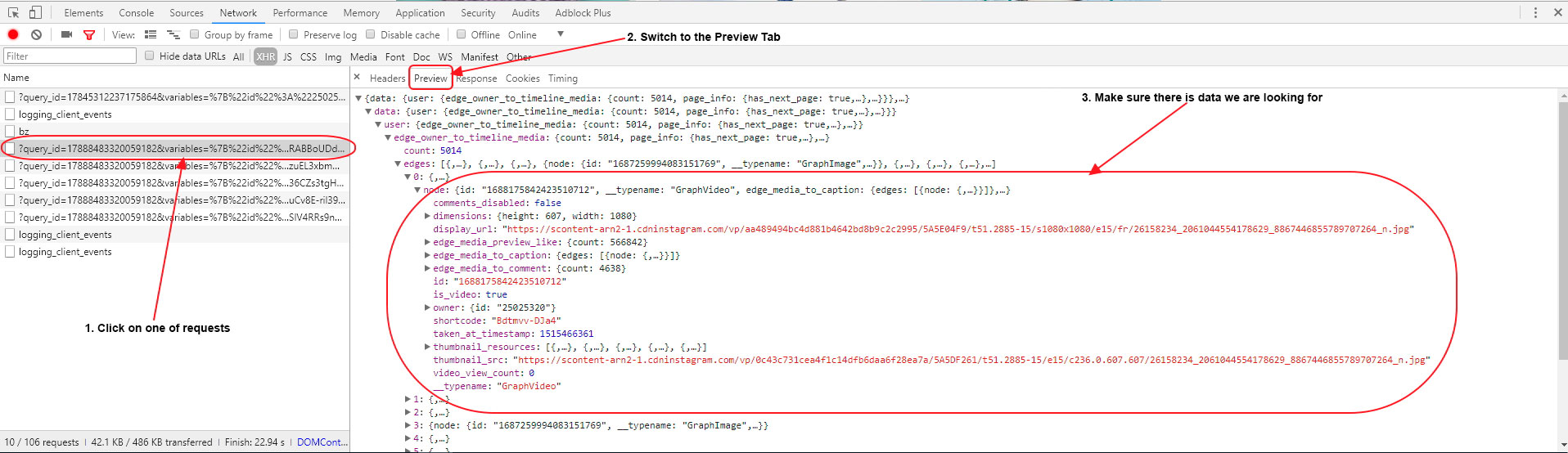
To make sure, we have to click on one of the requests and in the newly opened panel go to the Preview tab. There we can see the formatted content that the server returns to the browser for this request. Let’s get to one of the leaf elements in the tree and make sure that there are data about the images that we have on the page.
After making sure that these are the queries we need, let’s look at one of them more carefully. To do it, go to the Headers tab. There, we can find information about what URL is used to make the request, what is the type of that request (POST or GET), and what parameters are passed with the request.

It’s better to check query string parameters at Query String Parameters section. To see it, you need to scroll down the pane to the bottom:

As result of our analysis we get the following:
Request URL: https://www.instagram.com/graphql/query/
Request type: GET
Query string parameters: query_hash and variables
Obviously, some static id is passed as query_hash, which is generated by JS or exist either on the page, cookie or some JS file. There are also some parameters, which defines what exactly you get from the server are passed in the JSON format as the variables query parameter.
Now we need to understand where query_hash comes from. If we go to the Elements tab and try to find (CTRL + F) our query_hash e769aa130647d2354c40ea6a439bfc08, then we find out that it doesn’t exist on the page itself, which means that it is loaded or generated somewhere in the Javascript code, or comes with cookies. Therefore, go back to the Network tab and put the filter on JS. Thus, we can see only requests for JS files. Sequentially browsing the request by request, we have to search for our id in the loaded JS files: just click on the request, then open the Response tab in the opened panel to see the content of JS and do a search for our id (CTRL + F). After several unsuccessful attempts, we find that our id is in the following JS file:
https://www.instagram.com/static/bundles/ProfilePageContainer.js/031ac4860b53.js
and the code fragment that surrounds the id looks like this:
profilePosts.byUserId.get(n))||void 0===s?void 0:s.pagination},queryId:"e769aa130647d2354c40ea6a439bfc08",queryParams
So, to get query_hash, we need to:
- Load main channel page
- Find the URL to the file which filename contains ProfilePageContainer.js
- Extract this URL
- Load JS file
- Parse the id we need
- Write it into a variable for later use.
Now let’s see what data is passed as variables parameter:
{"id":"25025320","first":12,"after":"AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A"}
If we analyze all XHR requests that load data, we find that only the after parameter changes. Therefore id most likely is the id of the channel, which we need to extract from somewhere, first – the number of records that the server should return, and after is the id of the last record shown.
We need to find where we can extract the channel id. So the first thing we do is look for the text 25025320 in the source code of the main channel page. Let’s go to the Elements tab and do a search (CTRL + F) for our id. We find that it exists in the JSON structure on the page itself, and we can easily extract it:
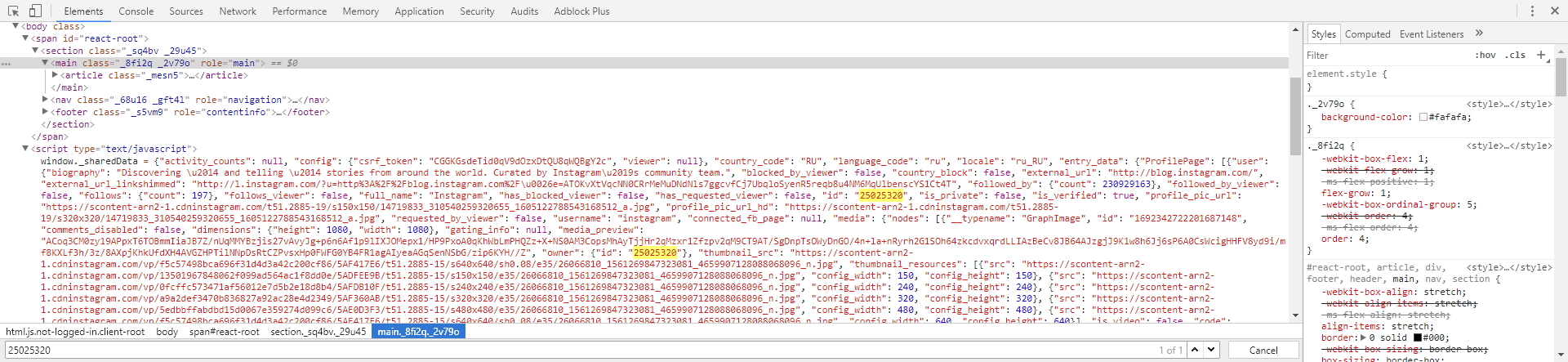
It seems everything is clear, but where do we get after value for each subsequent data loading? It is straightforward. Since it gets changed with each new loading, it’s most likely loaded with the data feed. Let’s look at the loaded data again more carefully:
We will see the following data structure there:
data: {
user: {
edge_owner_to_timeline_media: {
count: 5014,
page_info: {
has_next_page: true,
end_cursor: "AQCCoEpYvQtj0-NgbaQUg9g4ffOJf8drV2RieFJw1RA3E9lDoc8euxXjeuwlUEtXB6CRS9Zs2ZGJcNKseKF9f6b0cN0VC3ck8rnTfOw5q8nlJw"
}
}
}
}
where end_cursor looks like what we are looking for. Also, there is field has_next_page which can be very handy for us so we could stop loading feeds with data if there is no more data available.
Now we’ll write the beginning part of our Instagram scraper, load the main channel page and try to load the JS file with query_hash. Create a digger in your Diggernaut account and add the following configuration to it:
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:Set the Digger to the Debug mode. Now we need to run our Instagram scraper, and when the job is done, we are going to check the log. At the end of the log, we can see how the diggernaut works with JS files. It converts them into the following structure:
So the CSS selector for all JS script content will be script. Let’s add the query_hash parsing function:
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryidLet’s save our digger configuration and rerun it. Wait until it finishes the job and recheck the log. In the log we see the following line:
Set variable queryid to register value: df16f80848b2de5a3ca9495d781f98df
It means that query_hash was successfully extracted and written to the variable named queryid.
Now we need to extract the channel id. As you remember, it is in the JSON object on the page itself. So we need to parse the contents of a specific script element, pull JSON out of there, convert it to XML, and take the value we need using the CSS selector.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
# Parse only JSON content
- parse:
filter: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chidIf you look closely at the log, you can see that the JSON structure is transformed into an XML DOM like this:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz
US
1.5
480
360
profilePage_25025320
Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.
false
false
http://blog.instagram.com/
http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M
230937095
false
197
false
Instagram
false
false
25025320
false
true
5014
GraphVideo
false
607
1080
https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg
573448
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
It helps us build CSS selectors to get the first 12 records and the last record marker which we are going to use in after parameter for the request we send to the server to get next 12 records. Let’s write the logic for data extraction, and also let’s use a pool of links. We are going to iterate links in this pool and consequently add next page URL to this pool. Once next 12 records are loaded we are going to stop and see how loaded JSON is transformed to XML so we could build CSS selectors for data we want to extract.
Most recently, Instagram made changes to the public API. Now authorization is done not by using CSRF token, but by a particular signature, which is calculated with the new parameter rhx_gis, passed in the sharedData object on the page. You can learn used algorithm if you research JS of Instagram. Mainly its just MD5 sum of some parameters joined to a single string. So we use this algorithm and automatically sign requests. To do it, we need to extract the rhx_gis parameter.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# extracting JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
- exit
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chid
# Find elements where rhx_gis is kept
- find:
path: rhx_gis
do:
# Parse content of the current block
- parse
# Set parsed value to the variable rhxgis
- variable_set: rhxgis
# Find record elements and iterate over them
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Create new object named item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Find element where next page data kept
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page
- find:
path: has_next_page
do:
# parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read variable hnp to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, then find element with last shown record marker
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable with name cursor
- variable_set: cursor
# Apply URL-encode for the value (since it may contain characters not allowed in the URL)
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable with name cursor
- variable_set: cursor_encoded
# Form pool of links and add first link to this pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Set counter for number of loads to 0
- counter_set:
name: pages
value: 0
# Iterate over the pool and load current URL using signature in request header
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:Again, save the configuration and run the digger. Wait for completion and check the log. You should see the following structure for loaded JSON with next 12 records:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz
US
1.5
480
360
profilePage_25025320
Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.
false
false
http://blog.instagram.com/
http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M
230937095
false
197
false
Instagram
false
false
25025320
false
true
5014
GraphVideo
false
607
1080
https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg
573448
Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous
4709
1688175842423510712
true
25025320
Bdtmvv-DJa4
1515466361
150
150
https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
240
240
https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
320
320
https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
480
480
https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
640
640
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg
2516274
...
AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ
true
45ca3dc3d5fd
true
We shortened source code on purpose. We just removed all records from data except the first record. Since the structure is the same for all records, we need to see the structure of one record to build CSS selectors. Now we can define the logic of scraping for all fields we need. We are going to set the limit to the number of loads also, let’s say to 10. Moreover, add a pause for less aggressive scraping. As a result, we get the final version of our Instagram scraper.
---
config:
agent: Firefox
debug: 2
do:
# Load main channel page
- walk:
to: https://www.instagram.com/instagram/
do:
# Find all elements that loads Javascript files
- find:
path: script[type="text/javascript"]
do:
# Parse value in the src attribute
- parse:
attr: src
# Check if filename contains ProfilePageContainer.js string
- if:
match: ProfilePageContainer\.js
do:
# If check is true, load JS file
- walk:
to: value
do:
# Find element with JS content
- find:
path: script
do:
# Parse content of the block and apply regular expression filter to extract only query_hash
- parse:
filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\;
# Set extracted value to the variable queryid
- variable_set: queryid
# Find element script, which contains string window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# extracting JSON
- filter:
args: window\._sharedData\s+\=\s+(.+)\s*;\s*$
# Convert JSON to XML
- normalize:
routine: json2xml
# Convert XML content of the register to the block
- to_block
# Find elements where channel id is kept
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Parse content of the current block
- parse
# Set parsed value to the variable chid
- variable_set: chid
# Find elements where rhx_gis is kept
- find:
path: rhx_gis
do:
# Parse content of the current block
- parse
# Set parsed value to the variable rhxgis
- variable_set: rhxgis
# Find record elements and iterate over them
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Create new object named item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Find element where next page data kept
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page
- find:
path: has_next_page
do:
# parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read variable hnp to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, then find element with last shown record marker
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable with name cursor
- variable_set: cursor
# Apply URL-encode for the value (since it may contain characters not allowed in the URL)
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable with name cursor
- variable_set: cursor_encoded
# Form pool of links and add first link to this pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Set counter for number of loads to 0
- counter_set:
name: pages
value: 0
# Iterate over the pool and load current URL using signature in request header
- walk:
to: links
headers:
x-instagram-gis:
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Find element that hold data used for loading next page
- find:
path: edge_owner_to_timeline_media > page_info
do:
# Find element indicating if there is next page available
- find:
path: has_next_page
do:
# Parse content
- parse
# Save value to the variable
- variable_set: hnp
# Read the variable to the register
- variable_get: hnp
# Check if value is 'true'
- if:
match: 'true'
do:
# If yes, check loads counter if its greater than 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# If not, find element with the cursor
- find:
path: end_cursor
do:
# Parse content
- parse
# Save value to the variable
- variable_set: cursor
# Doing URL-encode
- eval:
routine: js
body: '(function () {return encodeURIComponent("")})();'
# Save value to the variable
- variable_set: cursor_encoded
# Add next page URL to the links pool
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D
# Calculate signature
- register_set: ':{"id":"","first":12,"after":""}'
- normalize:
routine: md5
- variable_set: signature
# Find record elements and iterate over them
- find:
path: edge_owner_to_timeline_media > edges > node
do:
# Create object with name item
- object_new: item
# Find element with URL of image
- find:
path: display_url
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: url
# Find element with record description
- find:
path: edge_media_to_caption > edges > node > text
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: caption
# Find element indicating if record is video or not
- find:
path: is_video
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: video
# Find element with number of comments
- find:
path: edge_media_to_comment > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: comments
# Find element with number of likes
- find:
path: edge_media_preview_like > count
do:
# Parse content
- parse
# Save value to the field of the object item
- object_field_set:
object: item
field: likes
# Save object item to the DB
- object_save:
name: item
# Increment loads counter by 1
- counter_increment:
name: pages
by: 1We hope that this article helps you to learn the meta-language and now you can solve tasks where you need to parse pages with infinite scroll without problems.
Happy Scraping!

Great article.
UPD : The query hash is now found in https://www.instagram.com/static/bundles/ProfilePageContainer.js/031ac4860b53.js.
Thank you for pointing it out. I made changes to the article.
What a nice post!! It help me a lot! just what I was looking for!!
Thanks from Mexico!!!
You are amazing! But we can also use https://github.com/LevPasha/Instagram-API-python
A kind of API made by a user and it has helped me achieve a lot. Try this but it is only for Python I think so, but check it out anyway.
Hello,
Requestion to https://www.instagram.com/graphql/query/?query_hash does not work any more.
Thus,the whole project doesn’t work.
It only grabbes first 12 posts.
Do you have any solution?
Thank you .
Thank you for reporting, we are going to check it shortly and update article. I will put a notice additionally.
Article has been updated to fit new JS structure, query_hash should be extracted now properly
Hi Mikhail, Instagram has changed their js structure again. It is also requiring x-instagram-gls. Is it still possible to scrape instagram like this?
Hi Nadia, thanks for commenting on it. We will check it today and update article.
Article has been updated to cover recent changes, later we will try to come up with more universal solution for query hash extraction as seems like they change JS structure pretty frequently.
Thanks again for pointing it out 🙂
This works like a charm! But, say I have a list of 15 instagram accounts to scrape, do I have to make a scraper for each and every one, or is there some way to make this scraper loop through a list of accounts?
You can use iterator to scrape multiple accounts, in this case beginning of your config will looks like:
Great Tutorial!
I have a question, does the query_hash changed sometimes? if so, it happens every day? week? month?
Thanks again!
Yes, it does change, so extracting it from the JS could be better idea than hardcoding it to the config. However, there is another issue – when they change JS structure query_hash may stop extracting. And we are hoping to come with more universal solution at some point. I cannot say how often they change query_hash, for me it look completely random.
Wow this article is amazing!
I am doing a scrapper for Instagram and it just helped me out a lot
I was nice that I also got to know this diggernaut tool
Hi,
Sorry, I was wrong. It still works the same way. Please don’t approve my last comment not to confuse anybody.
Thank you for this great article, this is exactly what I was looking for!
Cheers! 🙂
Hi, does this still work?
“Let’s run a small experiment, take the URL with the parameters that was used to load the data:”
results with a “not authorized” page. Do they check cookies now maybe?
No, it will not work this way anymore as Instagram using some parameter that should be calculated on the fly, so you cannot get it that simply in the browser anymore.
Hi, there!
Sorry if I’m asking stupid question, not enough imaginations.
As I understand, this is not official way to scrape and this is not an instagram API for developers.
So some limitations for API requests will concern for this kind of scrape method?
Or there are no limitations for it, so I can make endless requests and pull the data?
Thanks in advance!
This is web scraping process, it doesnt use API so no API limitations should be applied to it, but you need to be gentle when you scrape other resources, generally.
Great tutorial.
It seems that the graphql/query doesn’t work anymore
“https://www.instagram.com/graphql/query/?query_hash=3f1ec7fcdad5fb10359a6b14054721d3&variables=%7B%22tag_name%22%3A%22cat%22%2C%22include_reel%22%3Afalse%2C%22include_logged_out%22%3Atrue%7D”
We will check it out shortly and I’ll post comment later
Sorry for delay, we had checked revision of digger configuration posted in this article and it seems working fine. You cannot load this query request in the browser anymore because this request now requires special parameter to be sent with request headers. But this query works perfectly in the digger.
Any solution to make it work today, Mikhail?
We will check it this weekend (or earlier if it will be possible) and I’ll comment here
Catalin, Im really sorry about delay with my answer, but seems like solution posted in this article is still 100% working.
Thanks Mikhail!
It seems the queryId in js file is not a single one, in my case I can find 4 queryId in that js file, and all of them has the same prefix and suffix, so how to distinguish which one is correct?
e.g. try https://www.instagram.com/car/
Yes, its because instagram using different queryID to do different type of queries. To find one you need you need first to open developers tool in your browser, go to Network tab, then to XHR tab. After it you need to scroll page down so it loads more data. You will see new request appeared in XHR tab, if you click on it you can see which queryID is used. Then you need to search for it in JS to build proper regexp (as Instagram changes their JS structure frequently).
How can i use this in a website? whenever user’s click load more the scraper will work
Its possible to do using our API and data on demand functionality. You will need to pass last media id with the command to run digger. However you will need to modify this scraper to be able to work this way.
hey,please help.I request like you,and add one header calledx-instagram-gis,but it always return 403.
ps. now you can get ProfilePageContainer.js in the link tag where rel=”preload” and queryId in this file.I gusess this file path is different for area
x-instagram-gis should have checksum calculated using the specific algorithm (you can read it from digger code). Did you calculate it properly?
As for ProfilePageContainer, it’s in the link tag and in the script tag as well:
I met the same problem as ‘walter’, even I copy the url and x-instagram-gis from Instagram page to my code, it returns 403 still, so what am I missing?
I’ve also searched for how to calculate x-instagram-gis value, most of the answers point this one: MD5(
${rhxGis}:${variables}), rhxGis comes from JSON data from original page, variables is a JSON string like this: {“id”:”xxx”,”first”:12,”cursor”:”xxx”}I also tried this one, but it also returns 403.
Updated: I solved this problem, it’s only caused by my mistake when composing variables value…
thanks for your answer,i already noticed that need md5 the string.but i request with nodeJs,there are a module called crypto, you can see me code:
let crypto=require(‘crypto’)
let str=
${gisCode}:${JSON.stringify(variables)}//giscode is from the ShareData,and confirmed variables is right
let md5 = crypto.createHash(‘md5’);
let key = md5.update(str).digest(‘base64’)
what style should i use to md5,”base64″ or “hex”,i tested the both . it returns 403
updated:I have solved the md5 problem,but found another question.when i use the rhx_gis from the brower,it’s ok,i get the the data.but when i use the rhx_gis from the request by backend,i failed.. i also tried add cookie on header,helpless. how can this be,how can solve it . wanna your answer, thank you very much
do you get rhx_gis from JS code on the page?
of course,i can get the rhx_gis from JS code on the page.question is i use the nodejs to request someone’s ins page and get rhx_gis, then i combine with variables,at the last md5 that string, it failed,return 403. but i use the rhx_gis from brower(by console.log ) it’s ok ,return the data which i wanted. that makes me confused
may i send my code to you? i will make clearly Comment, and i think js code is easy to read
Sure, do you have it on GitHub, gitlab, bitbucket?
thanks you very much ,here is my github: https://github.com/webszy/insScraper,
insScraper.js is the code.
did you try to use
and it gave you 403?
your problem is in request options, this is how it should be (for the first request):
Does cookie is necessarily on the first request?I found the mid in the cookie is mean to be the deviceID,it is instagram define your platform,like web,web PC or android etc…
It’s not necessary, it determines platform using user agent you send
But you still need to use cookie jar I think, just don’t pre-set any cookie to it
i cannot say how much i thanks you , i delete the cookie and use your answer on the first request, it works.I truly appreciate your timely help.
Anytime, my friend 🙂
Hi Mikhail,
i couldnt find id value
my query_hash value= f92f56d47dc7a55b606908374b43a314
in response i couldnt get id
Hi, do you mean channel ID? Or some other ID?
no mre ProfilePAgeContainer.js
then how do proceed further and it doesn’t return any id
Hi, Instagram made some changes to their JS code, so we corrected the article to follow a new structure of JS code. Let me know if it solves your problem, if not, please provide more details, eg what entry page you are using. Instagram uses different query_hash for a different kind of content, so before I can give you some advice, I need to know what exactly you are trying to scrape.
if you trying to scrape tag search page, you have to load Consumer.js to extract query_hash, ProfilePageContainer.js has query hash for the channel
Hi Mikhail Sisin ,
i’m trying to scrape newyork tag and i want to get all the users who have posted in that particular tag .im using python and selenium to do this . when i do get request on the https://www.instagram.com/graphql/query/?query_hash=f92f56d47dc7a55b606908374b43a314&variables={“tag_name”:”bangalorefoodies”,”show_ranked”:false,”first”:7,”after”:”QVFEdXR3N25PZXpoaE9WbHZ5cHZqdWNnaUJiVVJRNVhHdDl0WVQ2U2xyYmtCSDF3X2xmdTRFRnpmeWZ1SkxWYXY3ejJsclFwT2ZKb3RaeW9VVDBlZWt0Ng==”}
I’m getting an error ,I doubt that the issue with headers and my headers are headers={“Accept”: “/“,
“Accept-Encoding”:”gzip, deflate, br”,
“Accept-Language”:”en-US,en;q=0.5″,
“Connection”:”keep-alive”,
“Cookie”:{“mid”:”XE5_pQAEAAFM1I8kUPda0O6Q3K3X”,
“rur”:”FRC”,
“mcd”:3,
“csrftoken”:”hWkYXneY0LQD3ZtGkfpzzdK7vXhiyds7″,
“urlgen”:[‘{\”14.143.78.141\”: 4755}:1go3Al:ILq5WGdzpLeXdkj0MNnai8N8Sys’],
},
“Host”:”www.instagram.com”,
“Referer”:”https://www.instagram.com/explore/tags/bangalorefoodies/”,
“User-Agent”:”Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36″,
“X-Instagram-GIS”:”6c48da4f326e454f1a1107f00a38e0cf”,
“X-Requested-With”:”XMLHttpRequest”
}
If you are using selenium, you don’t need to do these requests manually, you have to use the functions of the web driver you are using. Basically, you need to scroll to the bottom and then wait for load. Something like this:
Thanks for the reply Mikhail Sisin,
I was trying to scrape for instagram for shortcodes for a particular hashtag and when go to the viewsource i could get around 78 shortcodes and when i execute the script to scroll down i could get 2000 like that but the posts were above 1 lakh .And when i run the same script on different machines the shortcodes that i get varying drastically , couldn’t trace out what exactly the reason could be.
Even when it stops scrolling down when you try to scroll down still the page scrolls down.
Can you please help me out
Thanks in advance
Sir,
Please tell me about about Youtube’s infinite scrolling because it is totally different and confusing.
Thankyou
We will try to write an article for youtube in the next 2 weeks, keep checking our blog so you don’t miss it 🙂
Hi Mikhail,
my code in php and I don’t know you to generate x-instagram-gis in php. please tell me how I can generate in php
thanks
You have to create a JSON payload you will send to the server (check the code carefully to see how it’s formed), then get MD5 of this payload in hex format. This MD5 you should use as the value of the x-instagram-gis header. And make sure you are using the same User-agent for all your requests. As x-instagram-gis is using your user-agent.
Hi Mikhail! Great article.
Do you know where can I find the hash to scrape Media and comments? I tried your steps but no success.
Thanks and again, great job!
If you want to get comments for a specific post, you need to extract query_hash from another JS file: PostPageContainer.js. You need to look for current query_hash for this kind of content: f0986789a5c5d17c2400faebf16efd0d.
I dont know why but it dont work for me.
I translated your code above to Pascal-Object for my app and i always receive ‘403’ forbidden.
I think x-instagram-gis is not calculated correctly.
rhx-gis is hashed as string or as integer?
Thanks
As I understood, Evgeniy already helped you in our online chat. Let me know if you still have any questions.
Hi Mikhail,
I’m curious about how you figure it out all these? e.g., which file to find query_hash, and how the json composed.
Did you read all those JS files? I tried it, too, but it’s really hard to read since codes were obfuscated.
And if I want to scrap story from ins, where the query_hash should I looking for?
update: I can find the query_hash, but when I try to calculate the x-instagram-gis value as described, it seems failed, the value I got is different from the value on the request page. Any ideas?
First of all, make sure that all requests use the same user-agent. When they compose rhx_gis value, they use your user-agent value and in case if you forgot to set user-agent in the second request, you get an error. Some people do this mistake, so it’s better to double check.
Second, check the algorithm you are using:
1. Form the stringified JSON:
<%rhxgis%>:{"id":"<%chid%>","first":12,"after":"<%cursor%>"}all variables here should be filled with real values: rhxgis, chid and cursor.
2. Calculate MD5 of this string in HEX format, it will give you signature you should put to the header of your request
3. Make sure that URL you call has the field “variables” set and value if this field matches: {“id”:”<%chid%>“,”first”:12,”after”:”<%cursor%>“} you used for signature calculation. Also, make sure you URLEncode this value in your URL.
If your logic seems proper, but still doesn’t work, you can test it using values from the browser. Just get rhxgix from the browser, get variables and headers it sends. Then hardcode to your code and see if your signature you calculate for the hardcoded data matches the hardcoded signature. If it doesn’t match, you have an error somewhere in your code.
Sorry, I can calculate the right x-instagram-gis code when scroll for the next page, what I can’t is calculate the right x-instagram-gis cod for Instagram Story. The variables sent to query url is not same with scroll, it’s like this: variables: {“reel_ids”:[“12281817″],”tag_names”:[],”location_ids”:[],”highlight_reel_ids”:[],”precomposed_overlay”:false,”show_story_viewer_list”:true,”story_viewer_fetch_count”:50,”story_viewer_cursor”:””}
And if I use :{“id”:””,”first”:12,”after”:””} to get MD5, the result is not same as code on request header of x-instagram-gis.
Then you need to calculate GIS code using your actual query:
{“reel_ids”:[“12281817″],”tag_names”:[],”location_ids”:[],”highlight_reel_ids”:[],”precomposed_overlay”:false,”show_story_viewer_list”:true,”story_viewer_fetch_count”:50,”story_viewer_cursor”:””}and same query you should use in the URL in the “variables” fields.
Other words: query you use in the “variables” should match query you are using when calculating the checksum
GIS is acting like a signature for the query you are sending, so you need to sign exact query you are sending.
Yes, that’s what I do, but failed. Have you tried to fetch stories from Instagram?
No, do you have a link to some feed with stories?
Try this one: https://www.instagram.com/stories/arianagrande/ , only has data if user has story in the current day.
This is what you should send to the server as parameters:
query_hash: de8017ee0a7c9c45ec4260733d81ea31variables: {"reel_ids":["7719696"],"tag_names":[],"location_ids":[],"highlight_reel_ids":[],"precomposed_overlay":false,"show_story_viewer_list":true,"story_viewer_fetch_count":50,"story_viewer_cursor":""}This is the string (rhxgis should be replaced with read value) you need to get md5 for:
{"rhxgis":{"reel_ids":["7719696"],"tag_names":[],"location_ids":[],"highlight_reel_ids":[],"precomposed_overlay":false,"show_story_viewer_list":true,"story_viewer_fetch_count":50,"story_viewer_cursor":""}}And make sure you are logged in with your Instagram account because you cannot see stories if you are not logged in.
Yes, I did compose hash string like this. I think the reason for failing is I never logged in. Thanks.
Another question is: where does reel_ids come from?
From the same place as channel id. There is inline javascript on the page which initialize window._sharedData, there is JSON you can parse and get it:
{"StoriesPage":[{"user":{"id":"7719696",– you need ID of user.Hey, it’s actually now really hard to do. You need to open developer tools in your browser and watch the “Network” tab when you scroll the page down. Once next portion is loaded you will see new XHR request and if you check it you can see what query_hash is used for this kind of data. Then you can try to find where it loaded from (from what JS file). Yes, they are minified, but all you need to do is to search there query hash you already have. Then you just build the regexp to extract it from the JS file. Or.. you can even skip this step because query_hash is a more or less static value. They change it from time to time, but the most time it stays the same.
Mikhail,
I took your exact code and attempted to run it and it is throwing this error.
JSON Schema error: invalid character ‘-‘ in numeric literal
I tried to debug but I don’t know enough about diggernaut to extract the information I need to resolve this. Can you fix/help?
Hi, David. Looks like you placed digger config to the validator editor. And it caused the error you get. We fixed your digger, try to run it now.
Hi, all!
The instagram page no longer contains rhx_gis
What to do now is not clear 🙁
All right, if parameter “rhx_gis” is not present, you can leave it empty string.
I made such a conclusion based on this code from instagram:
e.getXHRSignature = function(t) {
var o = n(function(n) {
return n.rhx_gis
}) || ”;
return i(d[7])(o + ‘:’ + (t || ”))
}
Hello there. Instagram has recently removed rhx_gis from the sharedData JSON object, my scraper stopped working. What’s next?
Hi, you can use empty rhx_gis, as Max mentioned above. Our configs still works without changes.
Thank you! Yesterday I tried the empty rhx_gis and did not work. I was baffled, but it turned out I was just trying to scrape a private account without using the login cookies and that was the problem.
Hi! With or without rhx_gis param I have response with media where the user is tagged. What I’m doing wrong? Before couple of days everything works perfectly((
Here is the response for my second request to an account:
{
"data": {
"user": {
"edge_user_to_photos_of_you": {
"count": 2,
"page_info": {
"has_next_page": false,
"end_cursor": null
},
"edges": [
{
"node": {
"id": "1364176263937633098",
"__typename": "GraphImage",
"edge_media_to_caption": {
"edges": [
{
"node": {
"text": "some text"
}
}
]
},
"shortcode": "__________",
"edge_media_to_comment": {
"count": 2
},
"comments_disabled": false,
"taken_at_timestamp": 1476842504,
"dimensions": {
"height": 441,
"width": 640
},
"display_url": "https://instagram.fhel2-1.fna.fbcdn.net/vp/2ae47761518b7e9eba59af393a1711e8/5D7A39A5/t51.2885-15/e35/14714639_301552176897813_8628989751824744448_n.jpg?_nc_ht=instagram.fhel2-1.fna.fbcdn.net",
"edge_liked_by": {
"count": 212
},
"edge_media_preview_like": {
"count": 212
},
"owner": {
"id": "2996862408",
"username": "bigmarketingday"
},
"thumbnail_src": "https://instagram.fhel2-1.fna.fbcdn.net/vp/7cda9870488104e4938ce58cb378b252/5D6C1244/t51.2885-15/e35/c93.0.417.417a/14714639_301552176897813_8628989751824744448_n.jpg?_nc_ht=instagram.fhel2-1.fna.fbcdn.net",
"is_video": false,
"accessibility_caption": "No photo description available."
}
}
]
}
}
},
"status": "ok"
}
Hi, I don’t see anything wrong with the response you got. Why do you think it’s wrong. If you had auth issues (with gis) you wouldn’t get any data.
Hello,
Thank you for the post. I was able to follow howeevr, I am using googlesheet importxml function to import data. This has worked great except for pages with infinite scrolling. Do you know of a way to resolve this in googlesheets?
Thank you!
Hi. Unfortunately, we don’t have an expert that works so closely with google spreadsheets. So we cannot answer if it’s even possible, sorry.
Hi. I could retrieve the data using this method but I couldn’t retrieve the images data which is getting loaded before the scroll. I mean while loading the instagram handle no event is getting created with query hash. I am losing the data before the scroll. Is there any way I can get this?
Digger config we listed here gathers all data, before and after scroll. If you look carefully into the logic, you will see that it loads the first page, gets all data from the first page. Then starts to load additional data.
Hi. Thanks for posting this. I was trying to get the top liked images for a profile. https://www.instagram.com/aeolustours/ . Using the above method, I am getting only three images information from the query hash. How to retrieve the data before the page is getting scrolled?
Do you use listed digger config in your Diggernaut account?
hi.i need your help. i am working on scraping instagram stories.Did you find someway to get it without logged in ?
Hi, I succeeded to fetch images from Instagram for a long time until I met a new problem today: it still works on local, but in production, it can only find images by using a post url, and failed by using the account name, if log the response data, find out that can’t find the js file:
<script type="text/javascript" src="/static/bundles/metro/ProfilePageContainer.js/6c8f8cf618c0.js"
crossorigin="anonymous" charset="utf-8" async=""></script>
instead, find this one:
<script type="text/javascript" src="/static/bundles/metro/LoginAndSignupPage.js/5a0d1dc2ec1a.js" crossorigin="anonymous" charset="utf-8" async=""></script>
Do you know what’s the reason?
After some tests, I’m pretty sure that my server ip was added into the blacklist of Instagram, is there any solution?
You can try to use proxies
I would check a source of page Instagram returns and then it will be clear whats going on. If maybe that profile you are trying to access requires login.
Even those profiles need no login also failed to fetch and return the data shown above.
What happens if you use some proxy (better if the proxy is private, free proxies usually are not good)
I noticed that some third-party websites, like storyinsta.com, can fetch images with resolution higher than 1080p. I’m wondering if there’s a way to do that without using Instagram API, access_token, etc (www.instagram.com/developer/authentication).
You probably can use random size in the URL, but you will need to find out how to create a signature for new URL
Hi Mikhail, if it true that the rhx_gis is no longer available?
Moreover, I managed to get the query_hash, variable_id and after in python. Would you know how to generate the GET request in Python?
Many thanks in advance!
Hi Hans, yes rhx_gis is currently not used by instagram. As for python, it depends on what you use, if urllib2, you can check the documentation here: [https://docs.python.org/2/howto/urllib2.html](Python urllib2 documentation).
Hi, I found a strange thing: for the same image in instagram, the url I fetched is different from Saveig’s url. If I use these url in a link, click the link using my url will open a page to display the image, but click the url from Saveig will open a dialog to ask to save the image. Do you know the reason of this?
Example:
1. Original link: https://www.instagram.com/p/B_ncRzYDdNf/?utm_source=ig_web_copy_link
My url: https://scontent-hkg4-1.cdninstagram.com/v/t51.2885-15/e35/p1080x1080/95193631_370378523884285_1412269799237281274_n.jpg?_nc_ht=scontent-hkg4-1.cdninstagram.com&_nc_cat=101&_nc_ohc=TfEN6tMpS28AX_Wp86j&oh=20fbc9ef519dceaa807b6be7d5f370e1&oe=5EDCFF3B
Saveig url: https://scontent-msp1-1.cdninstagram.com/v/t51.2885-15/e35/p1080x1080/95193631_370378523884285_1412269799237281274_n.jpg?_nc_ht=scontent-msp1-1.cdninstagram.com&_nc_cat=101&_nc_ohc=TfEN6tMpS28AX8CQf6H&oh=5810bd5d79ae1f08f97aeb7f24f55acc&oe=5EDCFF3B&dl=1
Even if I add the &dl=1 still can not download it but only open it.
Hi, the reason is content-type server sends. In one case it sends mime-type that is set on your platform to be opened in the browser (eg image/png) and in the second case it sends application/octet-stream and it allows you to save file
New situation: when try to get the next page, it retuns: invalid query_hash. I think the rule of query hash changed again?
Make please guidance for facebook and youtube.
We will try and do it as soon as we can