
You know that there are many sites that uses RSS feed to distribute content. Many news websites use RSS. Almost all blogs have RSS feed enabled, a lot of other services uses RSS feeds. A good thing about such source is the same scraper you build can be used with RSS on any website source because it’s standardized and uses the same layout everywhere. RSS feed is a straightforward case, but since you just started to work with our meta-language, we have to start with simple stuff. So we will use Google News as source and teach you to create scrapers yourself.
We will use Google Chrome as our primary tool to work with the website. To start, we recommend you to install an extension for Google Chrome: Quick Javascript Switcher – it let you turn Javascript off and on for specific websites quickly. This is very handy tool as it let you see how the data is rendered on the page: on the server side or with Javascript (this can be data embedded in the JS on the page, a hidden block on the page that gets visible using JS, or the data is collected by an additional XHR (Ajax) request) . When we work with RSS feed, it’s not necessary to use this extension because RSS doesn’t use JS, but it’s advantageous when you work with HTML pages.
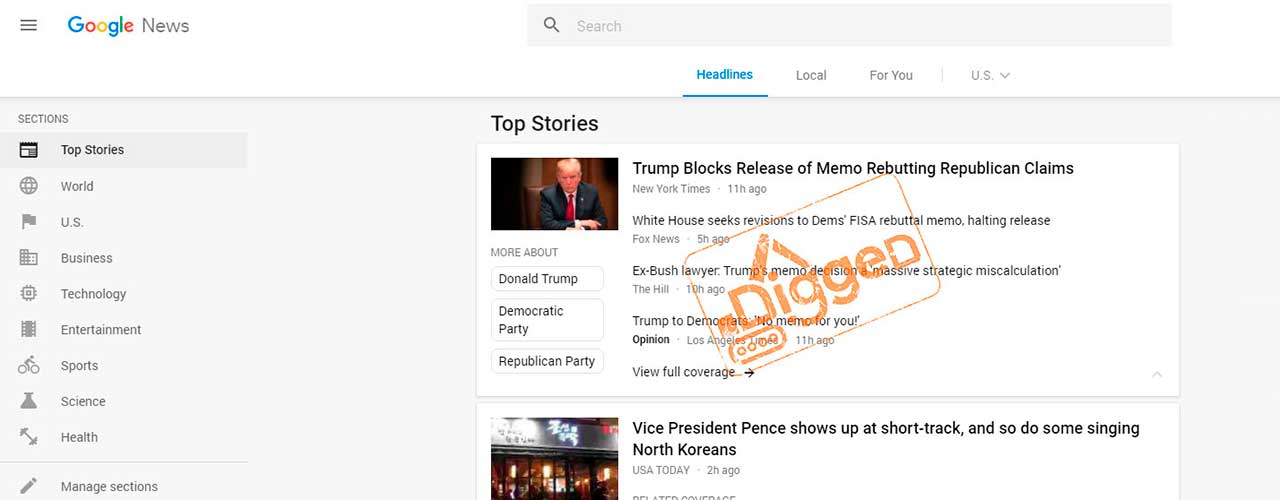
Let’s open the [page with the top news]https://news.google.com/news/?ned=us&gl=US&hl=en in the browser, press Ctrl+F to open search console and try to search word RSS. We can find the link we are looking for at the footer of the page.
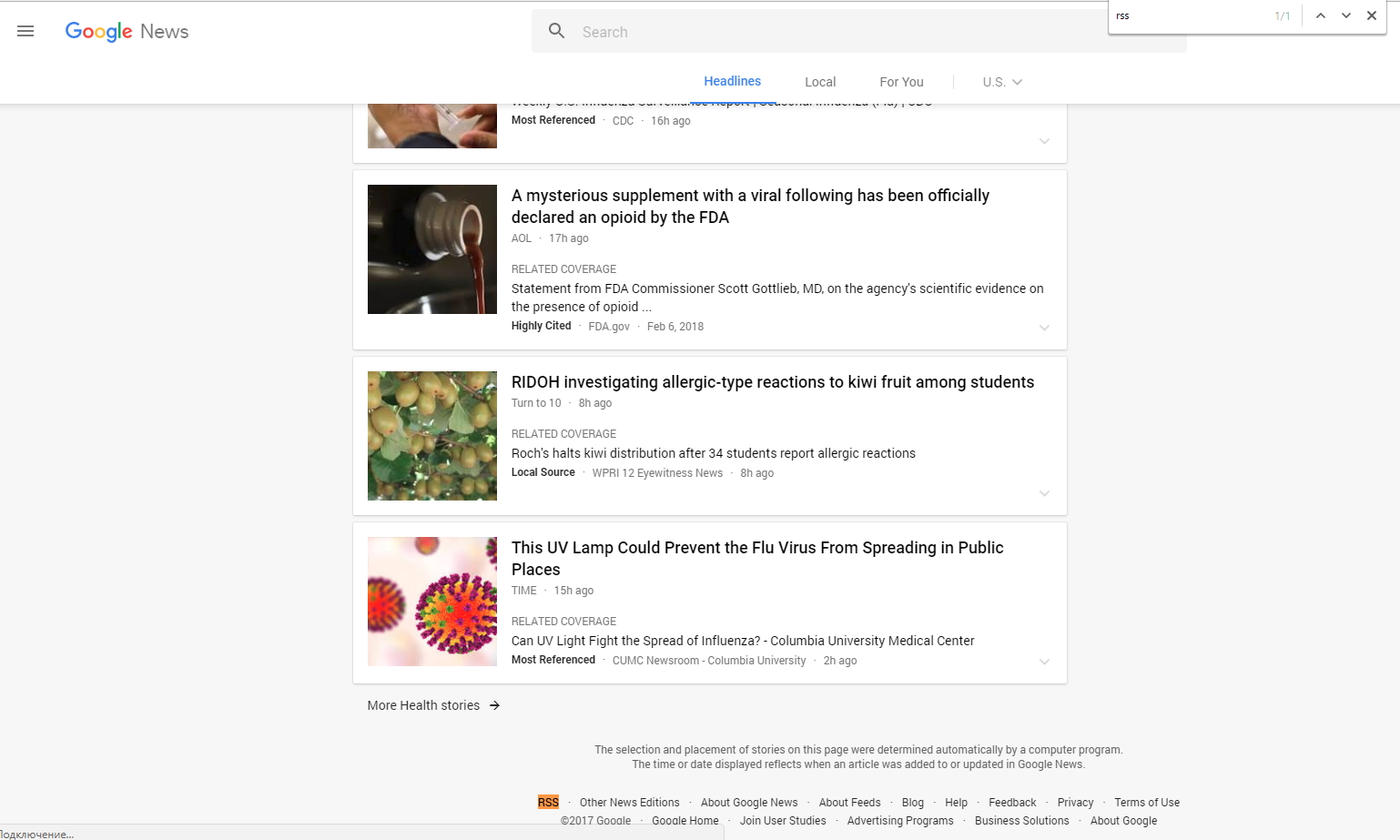
It’s not always you will find an RSS feed that easily, sometimes you may need to look in the page source, e.g., in our blog you need to open page source in your browser and search for RSS:
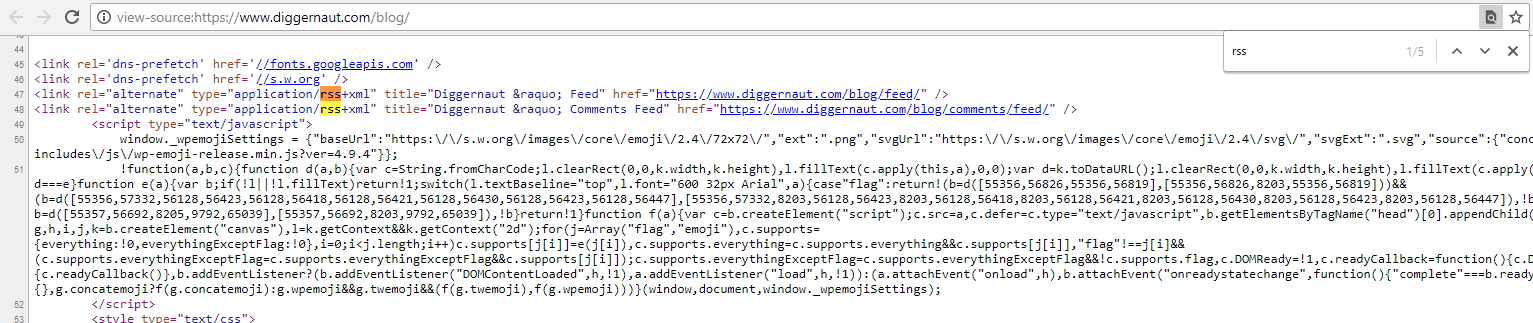
So now we need to pick the link to the RSS feed as we found it on the webpage. To do it you need to click the right button of your mouse on the “RSS” and select “Copy link address” option. It saves URL to the feed to your clipboard.
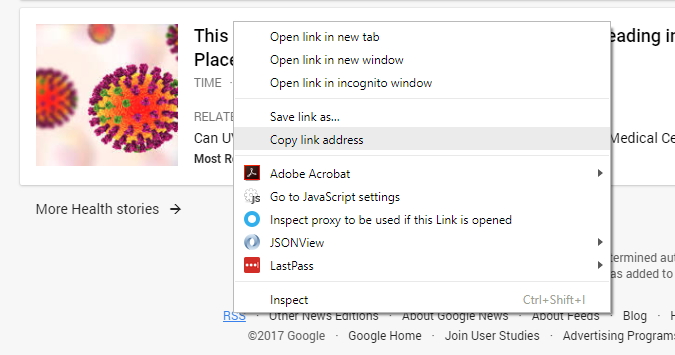
Now we need to paste (Ctrl + V) URL from the clipboard to the address field of the browser and load RSS feed to the browser. URL of RSS feed to Google Top News (just for your reference) is https://news.google.com/news/rss/?ned=us&gl=US&hl=en. Once you open it, you can see the XML source code for the RSS Feed. As you can see it has some header data blocks, we pick feed title from there to put it to our dataset so we could quickly identify a source of record in the future. It’s useful if you are gathering data from many sources. Also, you can find there many “item” blocks which contains news entries. It is data we want to scrape, so we need to have our scraper to iterate over these “item” blocks, extract data from them and put it as record fields to our dataset.
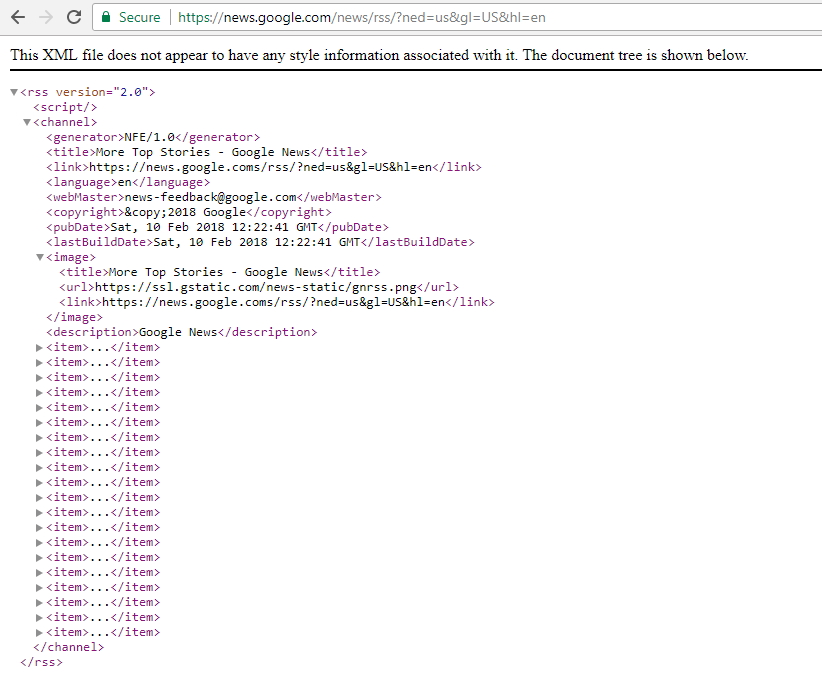
In the Diggernaut you traverse the DOM using CSS selectors. Once you load the page you are in the root of the loaded document, so we need to build our selectors from our current block (root). To get the title of the RSS feed, you need to extract text from the title tag, which is a child of the channel element. Our CSS selector for this field may be channel > title. Now let’s define selector for news items. Each item is enclosed into item tag, which is a child of the channel element. So again our CSS selector may be channel > item.
Since each news item has a specific structure and a few fields we would like to extract, let’s look at it more closely.

As our current block is item when we iterate over them, our selectors should be relative to the current block. So we can define news item selectors now:
- The headline is title
- URL to the source is link
- Category of the news item is category
- Date of publication is pubDate
- Description is description
That’s it for the basic RSS. Sometimes RSS items may include media items that could be scrapped as well, but not in the case of Google News. Also for this particular case, we see that we have HTML in the description that has links to the news, relevant to the event. We can extract them and use as nested objects. If you look into the first item, then you can see the following HTML source in the description (we prettified it, so it becomes a bit more readable):
To traverse this HTML DOM, we need first to parse it as HTML and then turn the register content into the block. Then digger can switch to the context of this block, and we jump to the root of this HTML structure and can easily navigate it. So let’s define CSS selectors for the elements we are going to extract data from to use it in our dataset. There is an image that we could probably use, and since there is just 1 image, we are going to have it in the primary news item object. As for relevant news, there may be many, so we are going to save them to our primary object as an array of the nested data objects. Each such nested object have URL to the source, headline and source name.
Navigating to the image element is easy. We are assuming that the table we have has only one row tr. If not, you may want to either pick just first row or iterate over rows. However, in the last case, you may need to store each such record as an element of the array of the nested objects (same as we are going to do with relevant news records). So in this particular case CSS selector to get image will be table tr > td > img.
Now, since we are going to put relevant news as nested data objects, we want to navigate first to the root element of each relevant news entry. The root element is li as we can see, but we also see that the first li is enclosed to the strong tag so ol > li selector is not going to work. To fix it, we can omit > telling selector that li is not only direct child of the ol. So our CSS selector may looks like: table tr > td > ol li.
Once we get to the relevant news item element, we need to extract URL, headline, and source. Again we have to use relative selectors:
- URL to the news a
- The headline is a (yes its same selector as URL but in case of URL we extract src attribute, and in case of headline we extract text content)
- The source is font
It seems like we defined all data we need to extract and decided what resulting data structure we use, now we can build our scraper:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Opening RSS feed
- walk:
to: https://news.google.com/news/rss/?ned=us&gl=US&hl=en
do:
# Navigating to the channel title element
- find:
path: channel > title
do:
# Extracting feed name to use as source name for our main records
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving data to the variable to put it later to each data record we will save to the DB
- variable_set: source
# Navigating to the news items and iterate over them
- find:
path: channel > item
do:
# Create main data object
- object_new: item
# Get value of the source variable and save it as item object field
- variable_get: source
- object_field_set:
object: item
field: source
# Navigate to the headline element
- find:
path: title
do:
# Extracting news headline
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the item object field
- object_field_set:
object: item
field: headline
# Navigate to the original source URL element
- find:
path: link
do:
# Extracting URL
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the item object field
- object_field_set:
object: item
field: url
# Navigate to the category element
- find:
path: category
do:
# Extracting category name
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the item object field
- object_field_set:
object: item
field: category
# Navigate to the publishing date element
- find:
path: pubDate
do:
# Extracting publishing date
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the item object field
- object_field_set:
object: item
field: date
# Navigate to the description element
- find:
path: description
do:
# Extracting description
- parse
# Saving value to the item object field
- object_field_set:
object: item
field: description
# Transform HTML content of the register to the block context
- to_block
# Navigate to the image element
- find:
path: table tr > td > img
do:
# Parse src attribute to get URL to the image
- parse:
attr: src
# Saving value to the item object field
- object_field_set:
object: item
field: image
# Navigate to the relevant news and iterate over them
- find:
path: table tr > td > ol li
do:
# Create new object for each relevant news
- object_new: relevant_item
# Navigate to the relevant news headline and URL element
- find:
path: a
do:
# Parse headline
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the relevant_item object field
- object_field_set:
object: relevant_item
field: headline
# Parse URL from href attribute
- parse:
attr: href
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the relevant_item object field
- object_field_set:
object: relevant_item
field: url
# Navigate to the relevant news source name element
- find:
path: font
do:
# Parse source name
- parse
# Doing general clean up for text data
- space_dedupe
- trim
# Saving value to the relevant_item object field
- object_field_set:
object: relevant_item
field: source
# Saving relevant_item object to the item object as nested object
- object_save:
name: relevant_item
to: item
# Save item object to the DB
- object_save:
name: itemYou need to create a new digger at the Diggernaut platform, copy and paste this digger configuration and run it. We hope that this material was useful and helped you to study our meta-language. As a result, you should get dataset like below:
[{
"item": {
"category": "More Top Stories",
"date": "Sat, 10 Feb 2018 03:00:44 GMT",
"description": "
- Kim Jong-un Invites South Korean Leader to North for Summit Meeting New York Times
- Fred Warmbier: North Korea 'not really participating' in Winter Olympics NBCNews.com
- North Korea Proposes Inter-Korean Leaders Summit Voice of America
- Is Otto Warmbier a symbol, or a prop? Washington Post
Full coverage
",
"headline": "Kim Jong-un Invites South Korean Leader to North for Summit Meeting",
"image": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRGBvn27fUWCyLnEZGnzZiOxVATjPOrdqiOcq0nTt8ZJ-5yFRcQSI3L-ZkyCPgViWdBtw5N1s-3QWJY",
"relevant_item": [
{
"headline": "Kim Jong-un Invites South Korean Leader to North for Summit Meeting",
"source": "New York Times",
"url": "https://www.nytimes.com/2018/02/09/world/asia/kim-yo-jong-history-facts.html"
},
{
"headline": "Fred Warmbier: North Korea 'not really participating' in Winter Olympics",
"source": "NBCNews.com",
"url": "https://www.nbcnews.com/storyline/winter-olympics-2018/fred-warmbier-north-korea-not-really-participating-winter-olympics-n846606"
},
{
"headline": "North Korea Proposes Inter-Korean Leaders Summit",
"source": "Voice of America",
"url": "https://www.voanews.com/a/north-korea-south-korea-summit/4247872.html"
},
{
"headline": "Is Otto Warmbier a symbol, or a prop?",
"source": "Washington Post",
"url": "https://www.washingtonpost.com/opinions/is-otto-warmbier-a-symbol-or-a-prop/2018/02/09/79c7c3ae-0dd2-11e8-8b0d-891602206fb7_story.html"
}
],
"source": "More Top Stories - Google News"
}
}
,{
"item": {
"category": "More Top Stories",
"date": "Sat, 10 Feb 2018 14:03:51 GMT",
"description": "Happy scraping!
