
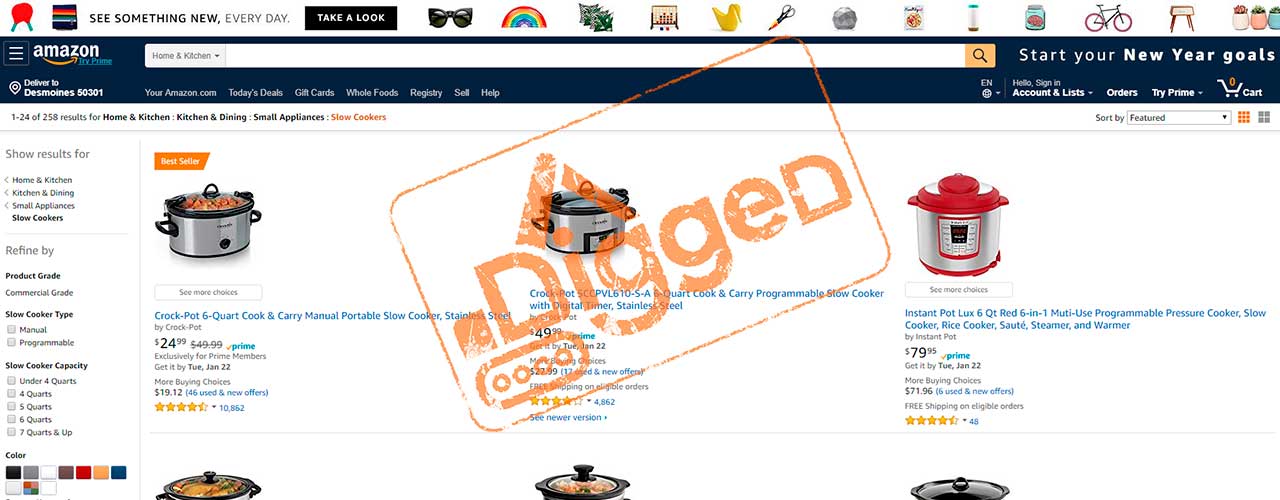
Today we are going to build a web scraper for Amazon.com. The tool will be designed to collect basic information about products from a specific category. If you wish, you can expand the dataset to be collected on your own. Or, if you do not want to spend your time, you have the opportunity to hire our developers.
Important points before starting development
Amazon renders the goods depending on the geo-factor, which is determined by the client’s IP address. Therefore, if you are interested in information for the US market, you should use a proxy from the USA. In our Diggernaut platform, you can specify geo-targeting to a specific country using the geo option. However, it only works with paid subscription plans. With a free account, you can use own proxy server. How to use them is described in our documentation in the link above. If you do not need a targeting by country, you can omit any settings in the proxy section. In this case, mixed proxies from our pool will be used. Of course, if you run the web scraper in the cloud. To reduce the chance of blocking, we will also use pauses between requests.
There is one more thing about which we want to tell you. Amazon can temporarily block the IP from which automated requests go. Different means can be used for it. For example, Amazon may show a captcha or a page with an error. Therefore, for the scraper to work successfully, we need to think about how it will catch and bypass these cases.
Bypassing Amazon.com captcha
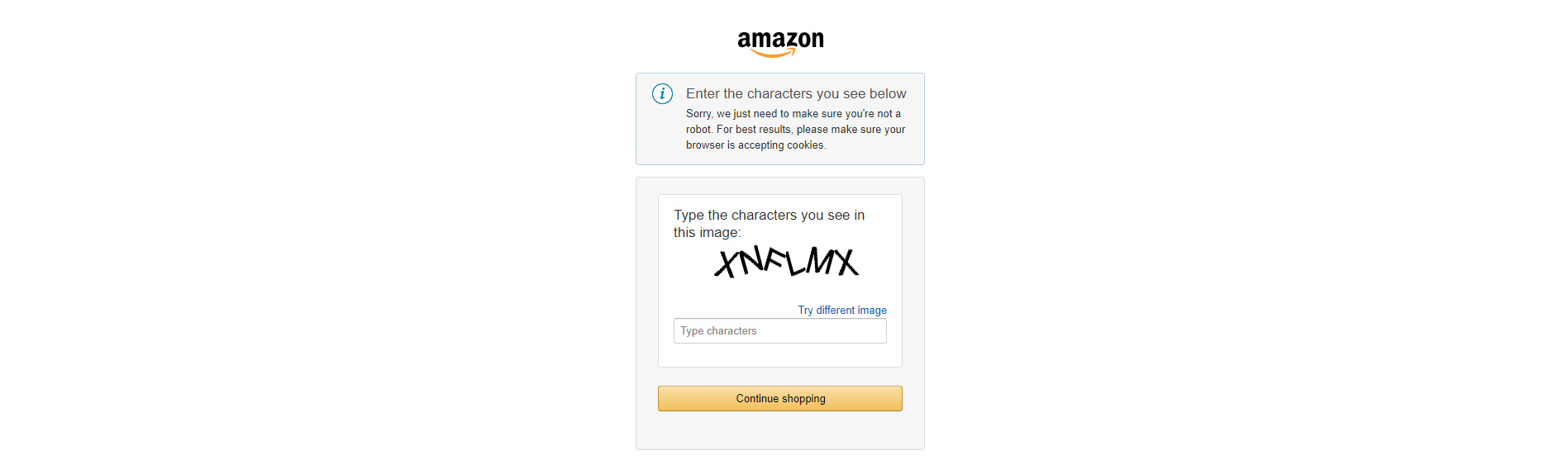
We will bypass the captcha with our internal captcha solution. Since this mechanism works as a microservice, it is available only when running the digger in the cloud, but it is free for all users of the Diggernaut platform. If you want to run the compiled digger on your computer, you will need to use one of the integrated services to solve the captcha: Anti-captcha or 2Captcha. You will also need own account in one of these services. In addition, you will have to change the scraper code a little. Namely, configure the parameters of the captcha_resolve command.
Bypassing the access error
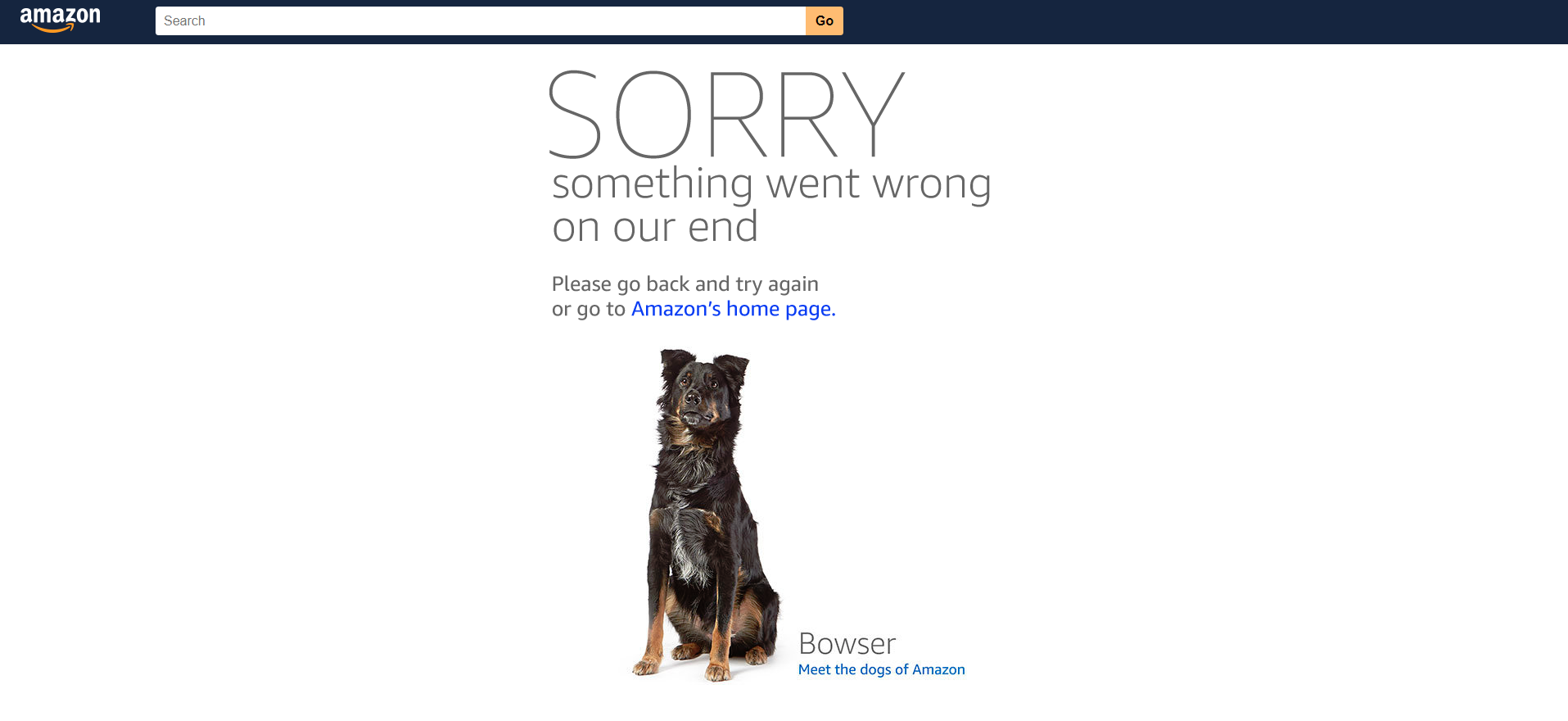
To bypass the access error, we will use proxy rotation and repeat mode for the walk command. This mode allows you to loop the page request until we say that everything went well. When rotating the proxy, the digger selects the next proxy from the list. If the list ends, the scraper returns to the first proxy. This function works both with the proxy specified in the config by the user and with the proxy in our cloud, which all users of the Diggernaut platform have access to.
Amazon Scraping Algorithm
Since the category has a paginator and many catalog pages with products, we will use the pool. It will allow us to describe the logic of parsing only once, for the entire pool, and not for each page separately. Take into account that the maximum number of pages in one category (or search query) given by Amazon is 400. Therefore, if there are more than 8000 products in your category and you want to collect the maximum quantity, then you need to revise the parameters of the search query, or you should collect products from subcategories. Our web scraper will be able to extract product information by any search request, so you can configure all the query filters in the browser and use the URL from the browser address bar as the start page in the config.
The algorithm will be as follows. We will create a pool and put a start page in it. Then we go to the pool, load the next page from it. Check if there is a captcha page. If so, we solve it and reload the page. Also, we check if Amazon has returned the access error. If so, we change the proxy and reload the page. If all checks are successful, then web scraper should parse the page and collect information about products. Next, we find the paginator, extract the link to the next page and add it to the pool.
Let’s look at the start page and define the CSS selectors that we need to find the paginator, the block with the product information and the fields to be extracted. To do it, we need Google Chrome and the developer tools built into it.
Find the CSS selector for listings (products)
Open the following URL in your browser:
https://www.amazon.com/s?bbn=16225011011&rh=n%3A%2116225011011%2Cn%3A284507%2Cn%3A289913%2Cn%3A289940&dc&fst=as%3Aoff&ie=UTF8&qid=1547931533&rnid=289913&ref=sr_nr_n_1
Press the right mouse button on the page and select the “Show code” option.
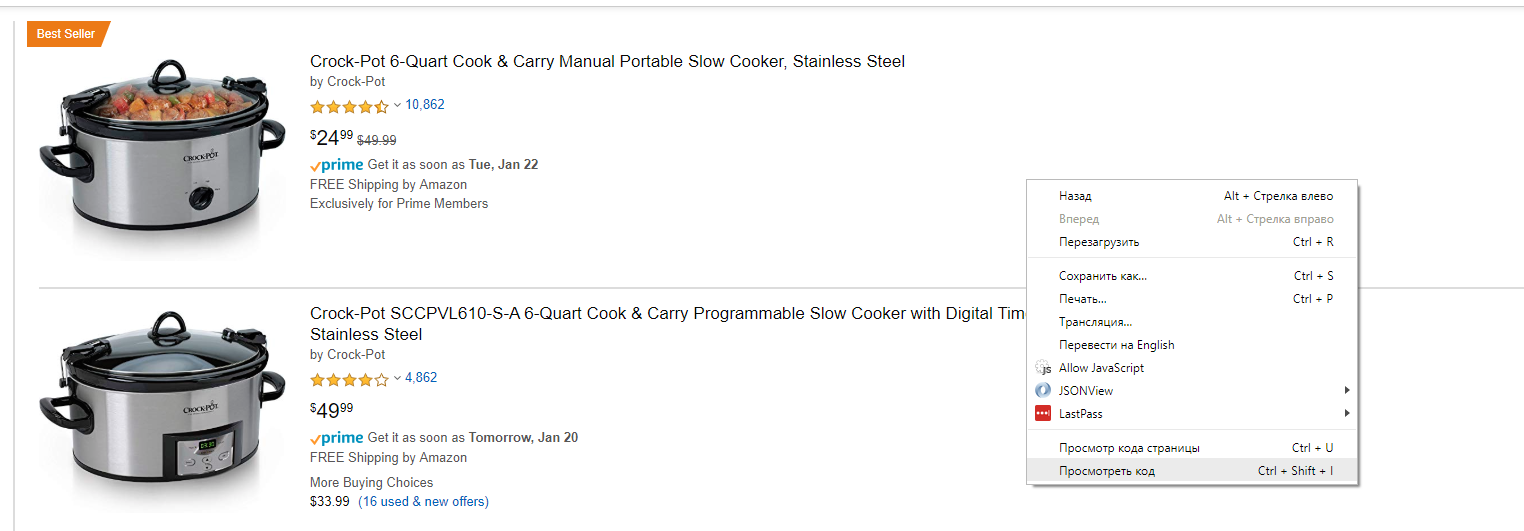
It will open a panel with developer tools. We are interested in a function for selecting an item on a page. Therefore, we activate this tool and select the first block with the product on the page. In the window with the source code of the page, you will immediately see the selected item.
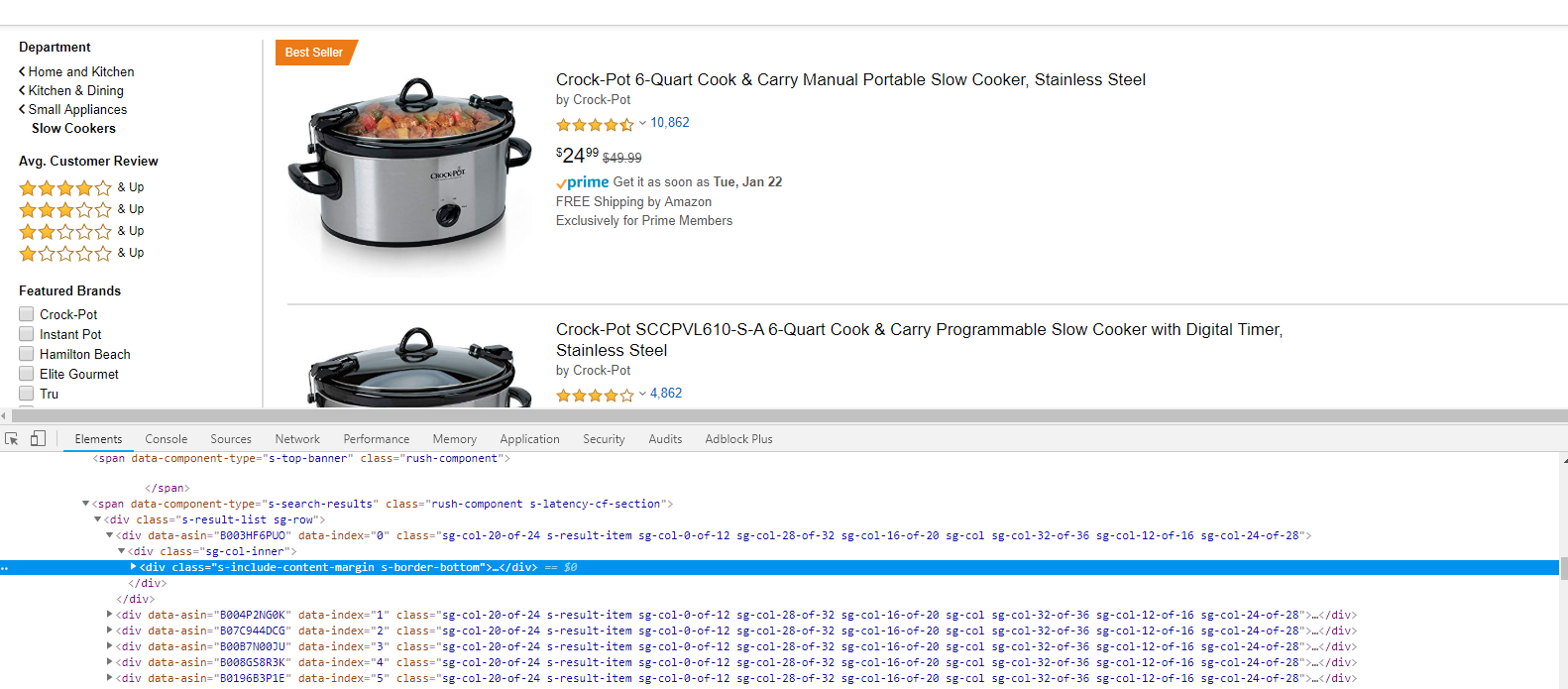
If you look closely at the HTML code in this part, you will see that all listings have the class s-result-item. Therefore, our listing selector will be: div.s-result-item.
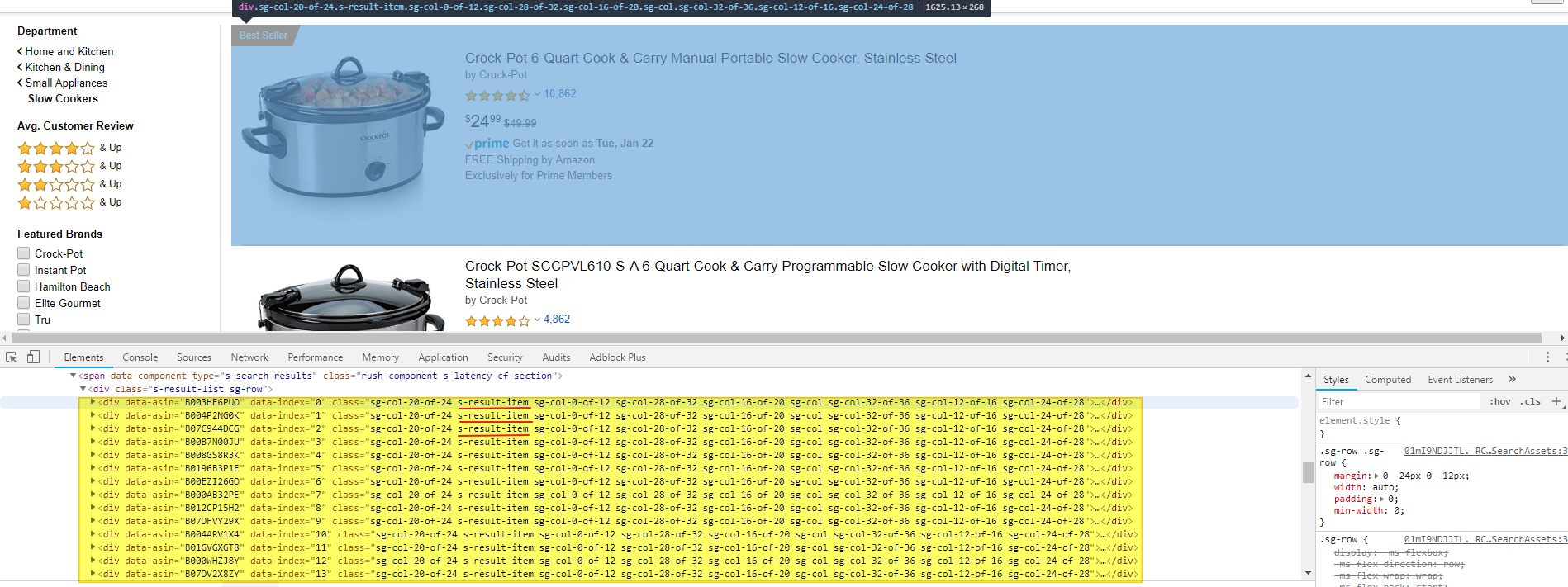
Find a paginator and define a CSS selector of the link to the next page
Paginator is at the bottom of the page.
Same way as with the finding listing selector, open the developer tools and select the “Next” button. We will see the selected element in the HTML source code of the page. It is the a tag inside the li tag with the a-last class. Therefore, our selector will be like this: li.a-last > a.
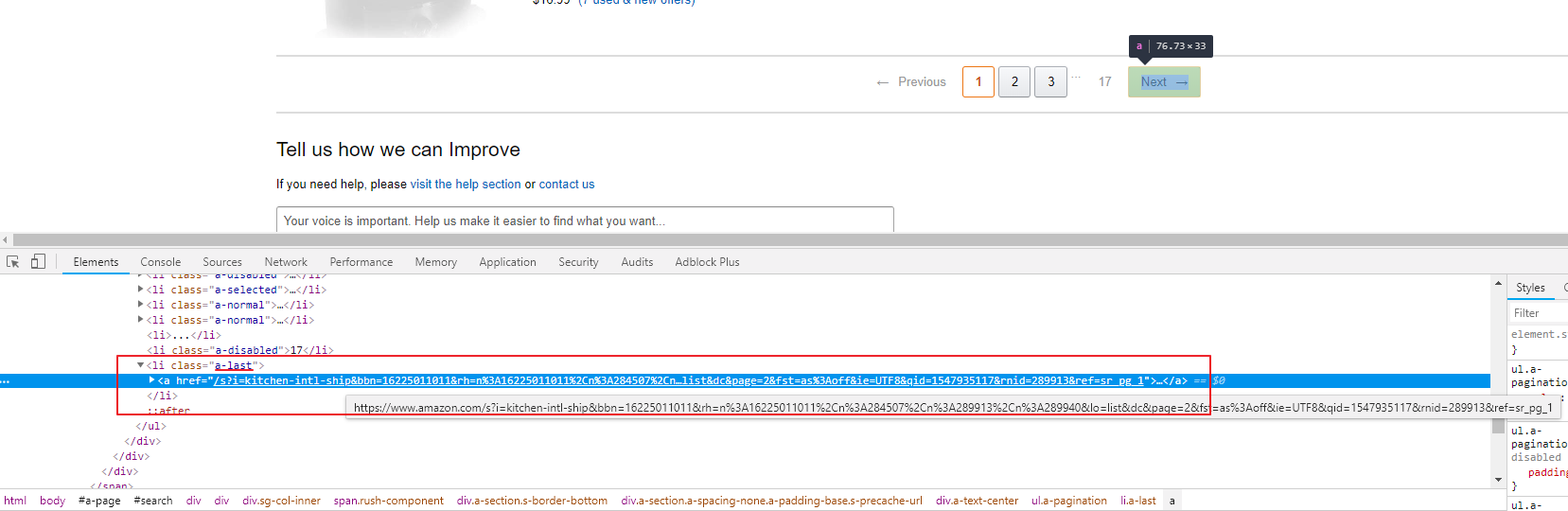
Now we have selectors for listings and the next page in the catalog. We can proceed to the extraction of selectors for product fields.
Selectors for listing fields

We can search for selectors on any of the products. The algorithm is the same as when we are getting any other selectors: we select a tool to select an element and click it on the page, watch and study the HTML fragment and extract a selector. But first, let’s take a close look at the item with the listing: div.s-result-item. This tag has an attribute data-asin. There is an ASIN (a unique identifier of the product variation in Amazon) stored. Having this ASIN, you can easily access the product page, since it can be formed using the following template: https://www.amazon.com/dp/<%ASIN%>, where is Amazon ASIN for the product. In the same way, a link to the page with offers from other sellers on Amazon can be formed: https://www.amazon.com/gp/offer-listing/<%ASIN%>. Therefore, we have to collect it and store in the data object field. The selector is not needed for it because it matches the listing selector. So when we switch to the listing block, we need to parse the attribute data-asin of the current block.
Product name – h5. There is only one h5 element in the listing block, so you can safely use this selector.
Brand. The brand is not as easy to extract, because all classes in the listing block are generalized and the brand block does not have a unique class or id. Therefore, we need to find some anchor to use. We know that we have only one h5 in the listing and that the block with the brand is in the same parent block with h5. It means that we can select the parent block using the haschild directive. This directive let you select an element that has a direct child element specified in the selector. In this case, the selector for the parent block will be: div.a-section:haschild (h5). Now we need to add a selector for the block with the brand relative to its parent block: div.a-color-secondary. As a result, we get the following selector: div.a-section:haschild(h5) > div.a-color-secondary. We also can see that in the block the brand is listed with the prefix “by”. Therefore, we will have to clean the data before storing it to the data object field using the normalize function.
Rating and the number of reviews. We see that the rating and the number of reviews are in the tags span. And these tags have an attribute aria-label. To select all the elements with this attribute, we can use the following selector: span[aria-label]. However, there are may be 2, 3, 4 or even 5 such elements in one listing. What should we do in this case? The slice option for the find command comes to rescue. Thus, we can select only the first element found (rating) and the second (number of reviews). Also for both fields, we will parse the contents of the aria-label attribute. However, the values in these fields contain additional text and symbols, and we want to get numeric values in our object with data. If we use the int and float types when storing the object field, then after the export of the dataset to Excel, numeric filters and sort will work properly for numeric columns. In addition, using the validation scheme for dataset, you can filter out unnecessary records by numeric value using numeric filters. So, to extract numeric values, we will use the filter option of the parse command.
Price. Everything is simple. The price is in the span tag with the class a-price. In this element, the price is presented in different formats. It will be easier to extract it from the element: span.a-price > span.a-offscreen. However, on some listings, there may be two prices if the product is sold with a discount. Therefore, we will use the slice option and select the first element found (element with index 0, since the numbering of the elements of the array starts from 0).
Prime – an icon indicating whether the product has free express delivery with the Amazon Prime subscription. The selector for this element is also simple since this icon has a unique class: i.a-icon-prime. It will work as follows. We store the default value (“no”) to the “prime” field. Then we search for the block with the icon and switch into it. Then store “yes” to the “prime” field. If the icon is in the listing, the scraper will go to this block and execute the specified commands. If not, the default value will remain in the field.
** Number of sellers **. We are not interested in sellers of used items, so we will collect only those items which indicate “new offers”. It will not give us entirely accurate data, because sometimes there are new and used product offers. So if you need to have exact numbers, you have to scrape the page with offers from other sellers. But in this particular case, we are ok with it. Selector for any link is a. However, in a listing block, there may be more than one link. Therefore, we are going to use the contains directive, which means that the selector should contain the specified text. Our selector should be like this: a:contains("new offers").
Link to the full-sized image The image selector is a very simple: img.s-image. However, the image in the src attribute is not full-sized. How to fix it? Let us open you a little secret. To make a full-sized one from a trimmed image in Amazon, you need to delete a small piece of the URL. Suppose in the src attribute we have the following URL:
https://m.media-amazon.com/images/I/81pMpXtqWrL._AC_UL436_.jpg. All we have to do is remove the _AC_UL436_ string between the points before the file extension and remove one of the two points. We will do it using the normalization function.
Catalog with a different layout
Sometimes Amazon shows the catalog using a completely different layout. It means such pages will have other selectors and selectors we defined already will not work there. We don’t know what the choice of one or another template depends on, but we have the opportunity to include logic for a variety of templates in the digger config. We will not go into the details of the selectors definitions, just list them below.
Listing selector: li.s-result-item
Next page selector: a.pagnNext
Product name: h2
Brand: div.a-spacing-mini:has(h2) > div.a-row > span (use slice and select last element)
Rating: i.a-icon-star>span
Reviews: div.a-spacing-none:has(i.a-icon-star) > a.a-size-small
Price: span.a-offscreen
Prime: i.a-icon-prime
Sellers: a:contains("new offers")
Link to the full-sized image: img.s-access-image
Now we have all the necessary selectors and a raw data processing plan. Let’s start writing the configuration of the web scraper.
Building the Amazon Web Scraper
Log into your account on the Diggernaut platform, create a new digger in any of your projects and click on the “Add config” button. Then just write the config with us, carefully reading the comments.
---
config:
debug: 2
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
do:
# Add start URL to the pool (you can add a list of start URLs)
- link_add:
url:
- https://www.amazon.com/s?bbn=16225011011&rh=n%3A%2116225011011%2Cn%3A284507%2Cn%3A289913%2Cn%3A289940&dc&fst=as%3Aoff&ie=UTF8&qid=1547931533&rnid=289913&ref=sr_nr_n_1
# Set variable to "yes" value to use it with repeat mode
# while value of this variable is "yes". the walk command will reload current page in the pool
- variable_set:
field: rip
value: "yes"
# Iterating links in the pool and loading them
- walk:
to: links
repeat_in_pool: <%rip%>
do:
# Expecting to the worse and set repeat variable to "yes" value
- variable_set:
field: rip
value: "yes"
# Switch to the title block to check if access if blocked
- find:
path: title
do:
# Parse value of title to the register
- parse
# Check if there is word "Sorry"
- if:
match: Sorry
do:
# If so, access is blocked, so we switch the proxy
- proxy_switch
else:
# If not, then access is allowed. Check if there is captcha on the page.
# Switch to the body block. Please note of option "in" usage.
# Right now we are in the "title" bvlock and there is no body tag inside of it
# so we should search for body block in full document intead of current block
# to do it you can use option in: doc
- find:
path: body
in: doc
do:
# Parse entire page text to the register
- parse
# Check if there is specified string in the text
- if:
match: Type the characters you see in this image
do:
# If so, we have a captcha on the page and we need to solve it
# to do it we need to extract some parameters from the page and save them to variables
- find:
path: input[name="amzn"]
do:
- parse:
attr: value
- normalize:
routine: urlencode
- variable_set: amzn
- find:
path: input[name="amzn-r"]
do:
- parse:
attr: value
- normalize:
routine: urlencode
- variable_set: amznr
# Switch to the block with captcha image
- find:
path: div.a-row>img
do:
# Parse URL of the image
- parse:
attr: src
# Load the image
- walk:
to: value
do:
# In imgbase64 block we will have an image encoded as base64
# This is how Diggernaut works with binary data
# Any binary file is encoded as base64 and you can work with it
# using other Diggernaut functionality (such as OCR, save files etc)
- find:
path: imgbase64
do:
# Parse block content
- parse
# save it to the capimg variable
- variable_set: capimg
# Use command for solving captcha
# Use "diggernaut" as provider to use in-house captcha solver
# Our captcha type is "amazon"
# Also we should pass image with captcha here, using variable capimg
- captcha_resolve:
provider: diggernaut
type: amazon
image: <%capimg%>
# After captcha_resolve exacution we should have
# recognized captcha text in the "captcha" variable
# so we read this variable value to the register
- variable_get: captcha
# And check if there is any value
- if:
match: \S+
do:
# If captcha recognized, we are sending captcha answer to Amazon server
- walk:
to: https://www.amazon.com/errors/validateCaptcha?amzn=<%amzn%>&amzn-r=<%amznr%>&field-keywords=<%captcha%>
do:
else:
# String not found, so page is without captcha
# and we are working with standard catalog page
# Turn off repeat mode for the current page
- variable_set:
field: rip
value: "no"
# Pause for 5 sec
- sleep: 5
# Start parsing process
# First lets get next page and push to the pool
- find:
path: li.a-last > a, a.pagnNext
do:
# Parse href attribute
- parse:
attr: href
# Check if there is value in href
- if:
match: \w+
do:
# If so put it to the pool
- link_add
# Extract listings, jump to each listing
# First layout
- find:
path: div.s-result-item
do:
# Parse data-asin attribute to get ASIN
- parse:
attr: data-asin
# Check if ASIN is in register
- if:
match: \w+
do:
# Create new data object
- object_new: item
- object_field_set:
object: item
field: asin
# Lets generate URL to product page
# Save ASIN to variable
- variable_set: asin
# Write string to the register and then save URL to the object field
- register_set: https://www.amazon.com/dp/<%asin%>
- object_field_set:
object: item
field: url
# Extract product name
- find:
path: h5
do:
- parse
# Normalize whitespaces
- space_dedupe
# Trim the register value
- trim
# Save register value to the object field
- object_field_set:
object: item
field: title
# Extract brand
- find:
path: div.a-section:haschild(h5) > div.a-color-secondary
do:
- parse
- space_dedupe
- trim
# Remove "by" word
- normalize:
routine: replace_substring
args:
^by\s+: ''
- object_field_set:
object: item
field: brand
# Extract rating
- find:
path: span[aria-label]
slice: 0
do:
- parse:
attr: aria-label
filter: ^([0-9\.]+)
# Check if rating value is exist
- if:
match: \d+
do:
# Save value to the object field as float type
- object_field_set:
object: item
field: rating
type: float
# Extract reviews
- find:
path: span[aria-label]
slice: 1
do:
- parse:
attr: aria-label
filter: (\d+)
- if:
match: \d+
do:
# Save value to the object field as int type
- object_field_set:
object: item
field: reviews
type: int
# Extract price
- find:
path: span.a-price > span.a-offscreen
slice: 0
do:
- parse:
filter:
- ([0-9\.]+)\s*\-
- ([0-9\.]+)
- object_field_set:
object: item
field: price
type: float
# Extract prime
# Dafault it to "no"
- register_set: "no"
- object_field_set:
object: item
field: prime
- find:
path: i.a-icon-prime
do:
- register_set: "yes"
- object_field_set:
object: item
field: prime
# Extract sellers
- find:
path: a:contains("new offers")
do:
- parse:
filter: (\d+)
- object_field_set:
object: item
field: sellers
type: int
# Extract image
- find:
path: img.s-image
do:
- parse:
attr: src
# Replace substring in URL to make it full-sized
- normalize:
routine: replace_substring
args:
\.[^\.]+\.jpg: '.jpg'
- normalize:
routine: url
- object_field_set:
object: item
field: image
- object_save:
name: item
# Second layout
- find:
path: li.s-result-item
do:
- parse:
attr: data-asin
- if:
match: \w+
do:
- object_new: item
- object_field_set:
object: item
field: asin
- variable_set: asin
- register_set: https://www.amazon.com/dp/<%asin%>
- object_field_set:
object: item
field: url
- find:
path: h2
do:
- node_remove: span.a-offscreen
- parse
- space_dedupe
- trim
- object_field_set:
object: item
field: title
# Slice here will select just last found element
- find:
path: div.a-spacing-mini:has(h2) > div.a-row > span
slice: -1
do:
- parse
- space_dedupe
- trim
- object_field_set:
object: item
field: brand
- find:
path: i.a-icon-star>span
do:
- parse:
filter: ^([0-9\.]+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: rating
type: float
- find:
path: div.a-spacing-none:has(i.a-icon-star) > a.a-size-small
do:
- parse:
filter: (\d+)
- if:
match: \d+
do:
- object_field_set:
object: item
field: reviews
type: int
- find:
path: span.a-offscreen
slice: -1
do:
- parse:
filter:
- ([0-9\.]+)\s*\-
- ([0-9\.]+)
- object_field_set:
object: item
field: price
type: float
- register_set: "no"
- object_field_set:
object: item
field: prime
- find:
path: i.a-icon-prime
do:
- register_set: "yes"
- object_field_set:
object: item
field: prime
- find:
path: a:contains("new offers")
do:
- parse:
filter: (\d+)
- object_field_set:
object: item
field: sellers
type: int
- find:
path: img.s-access-image
do:
- parse:
attr: src
- normalize:
routine: replace_substring
args:
\.[^\.]+\.jpg: '.jpg'
- normalize:
routine: url
- object_field_set:
object: item
field: image
- object_save:
name: item
You can also download sample of Amazon dataset
