
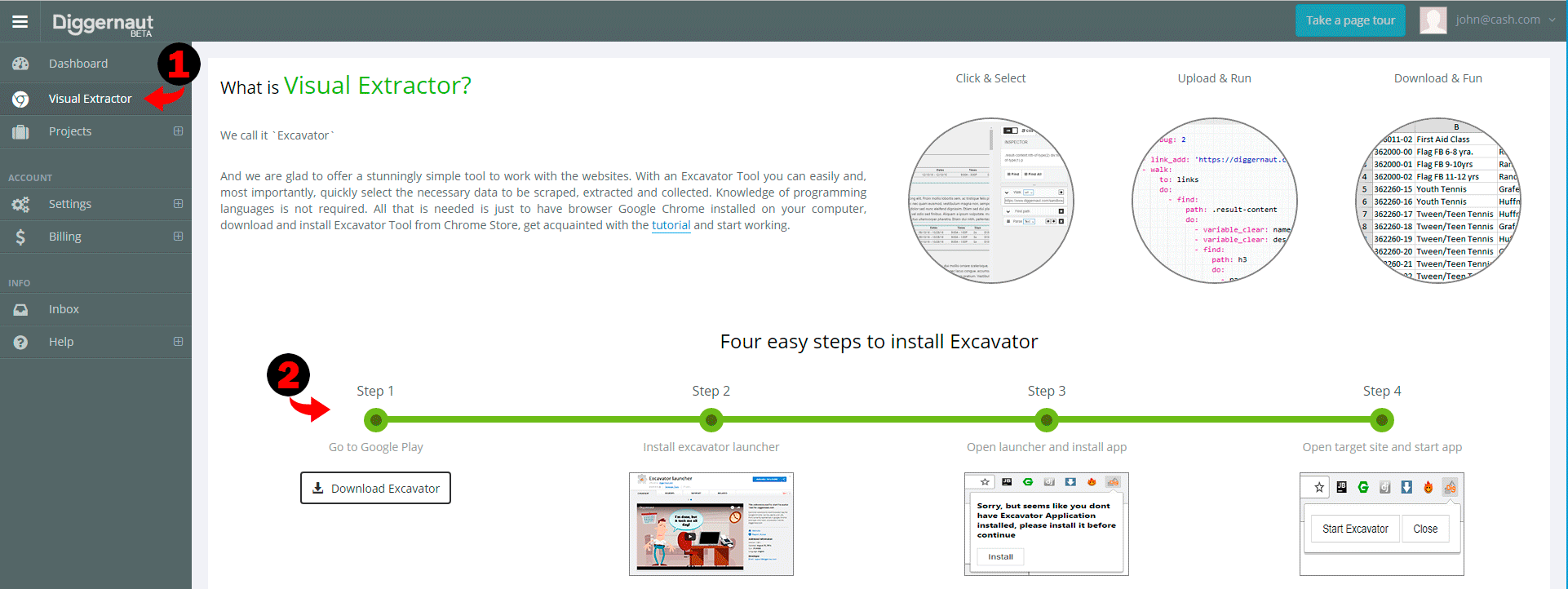
This article can be used for educational purposes if you want to learn how to work with our Excavator application. We assume that you already have Excavator application installed, if not, please log in to your Diggernaut account, then go to Visual Extractor section and follow instructions to install it.
So first lets open El Paso Sheriff Blotter website in Google Chrome browser, click on Excavator icon and then on “Start Excavator” button.
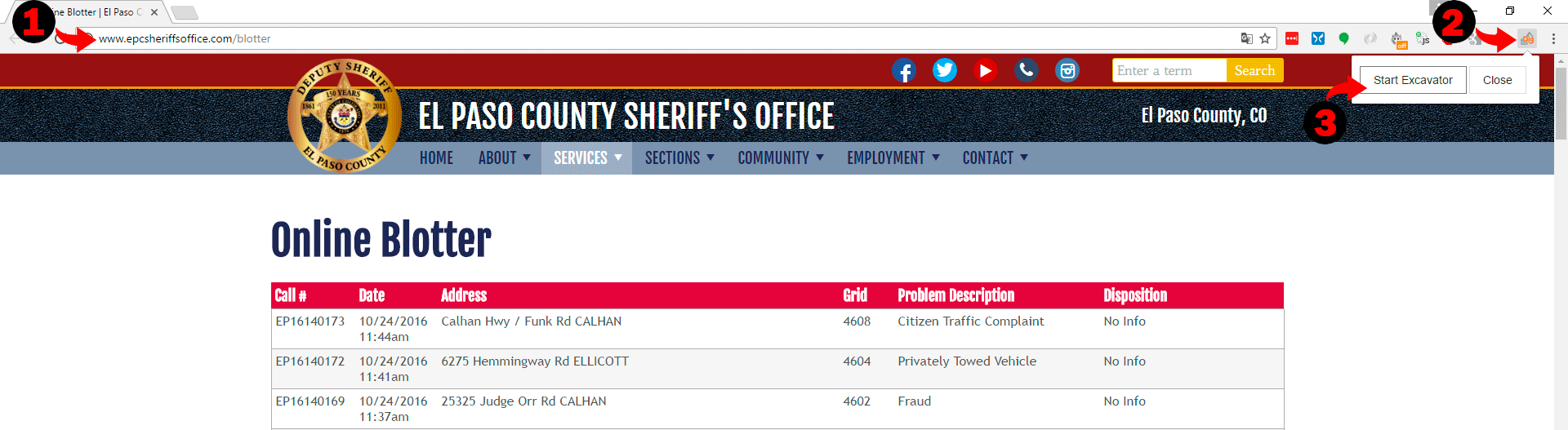
You should see the application opened and in few seconds website will be loaded to the application. Once it’s done, we can start to work with it.
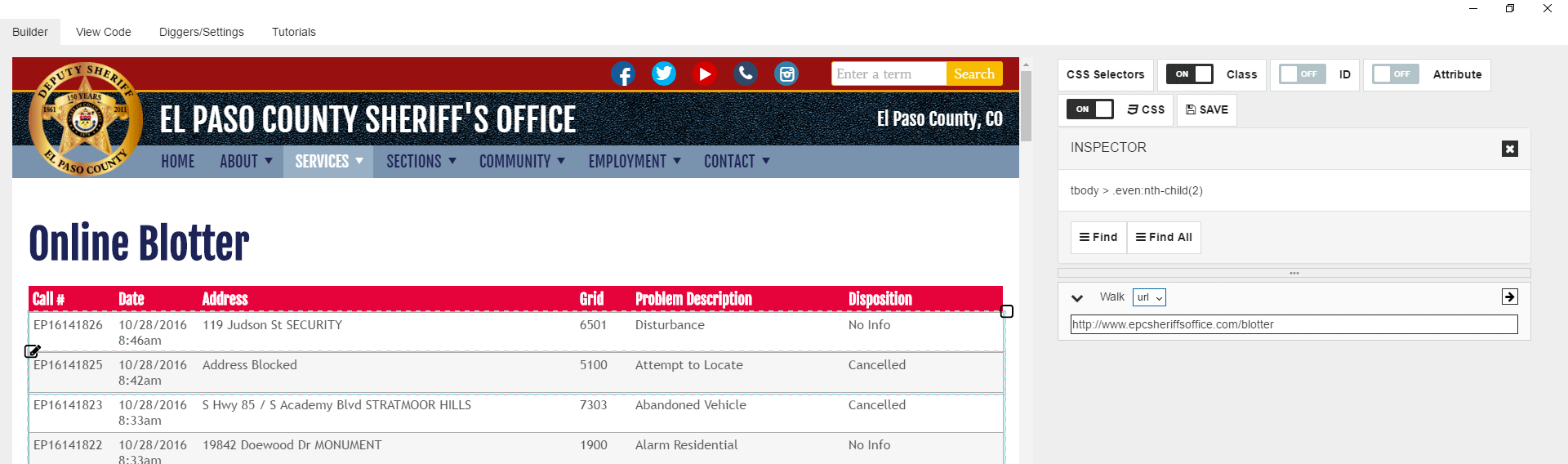
First, take a look at the CSS Selector option on top of right side of the application. There you can turn on and off classes, ids, and attributes. The property shall not be used in CSS pathing if it’s turned off. Usually, we have classes turned on as it gives good results in most cases, but sometimes you may want to turn it off. On this page, we can see that each table row has classes like .even and .odd. So if we use classes in CSS selectors, we cannot select all table rows with a single “Find” command. We have to get through .even and .odd rows separately. However, it also means you need to duplicate main logic block twice. It’s not a good way to do. To avoid it we can turn Off classes for CSS selectors, and we can select all table rows with a single “Find” command.

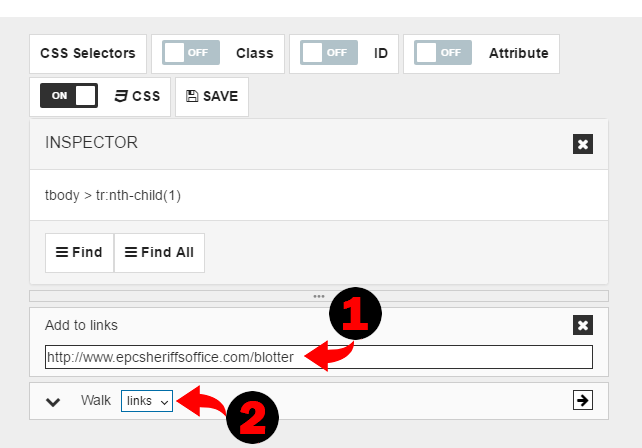
Then lets change way how we load the first page. Since we need multiple pages, and there is paginator on the page, would be better if we use links pool and iterate over URLs in this pool. So instead of walk to the first page, lets first add it to the links tool and then walk to the pool. To do it we need to drag “Add to links” command.
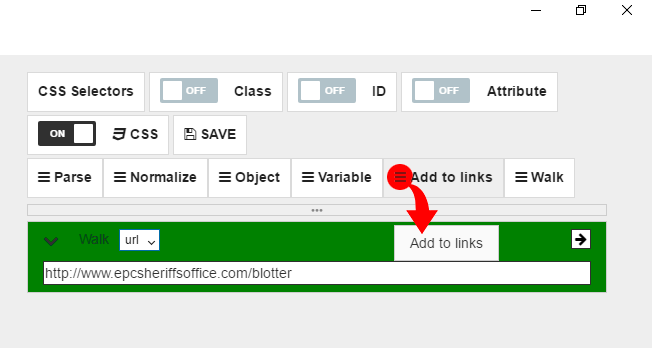
Let’s copy & paste URL from “Walk” command to “Add to links” command. Then finally change “Walk” command mode to “links”.
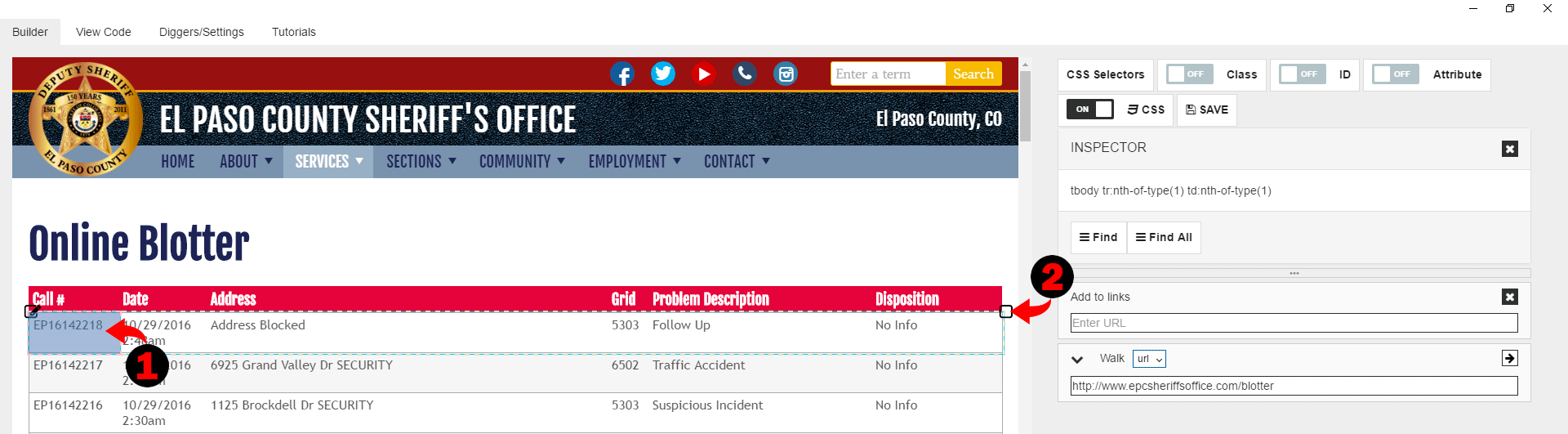
Now let’s click on the first (or any other) cell in the first row of the table with data. You can see that you selected the cell only, but not the whole row. Its true, very often you cannot select a row by just clicking on it, as cells overlay row entirely. To solve this problem and select row you can use the “Select Parent” icon to select the parent of a cell, which is a row. So let’s click on it, and you see that you have now the whole row selected.
Next step we need to pull “Find all” command to the “walk” block, as we need to select all rows in the table.
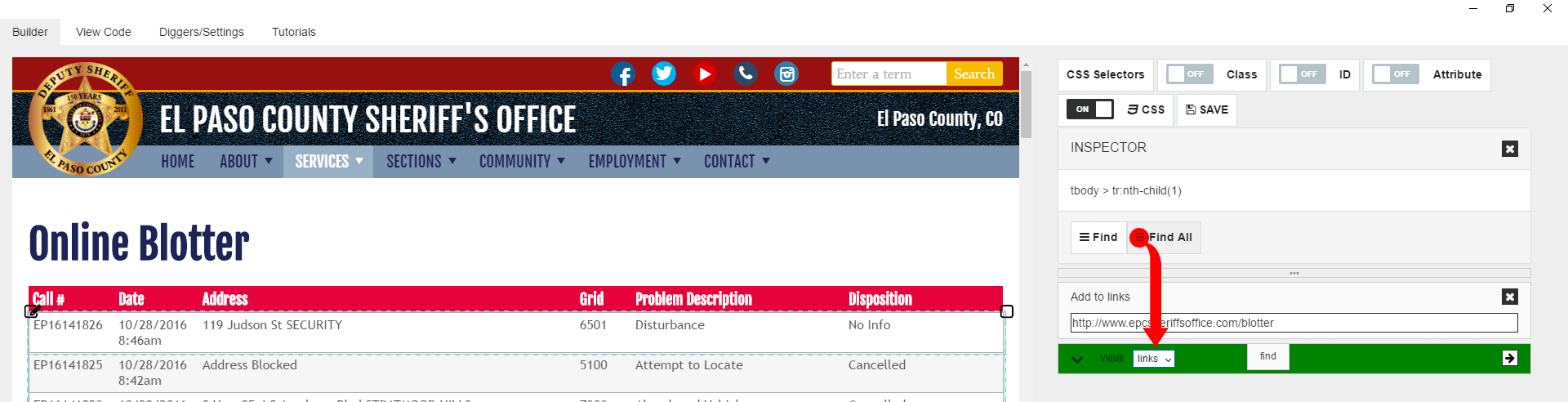
If you move the mouse over “Find” command now, you see that it selects all rows in the table. You also can see that “Find” command has “Parse” block inside. Since we are not going to parse content in the row and instead we are planning to walk into each cell to get data separately, we need to delete “Parse” command from “Find” block by clicking on delete icon.
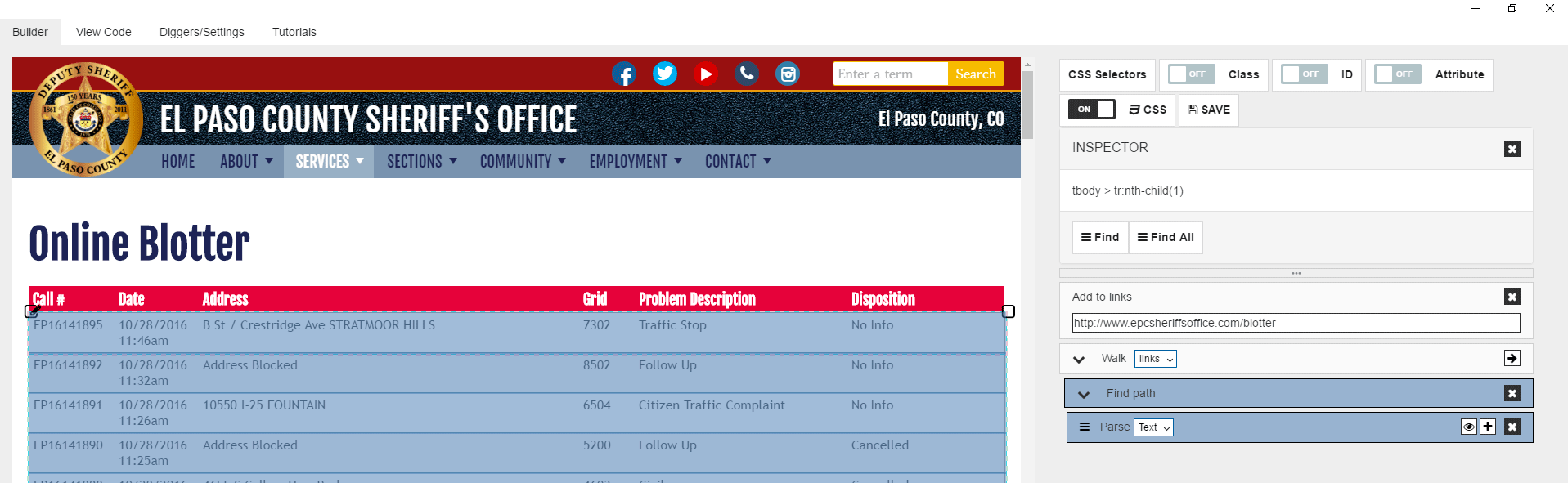
Lets now turn on classes for CSS selectors as generally, it helps a lot.
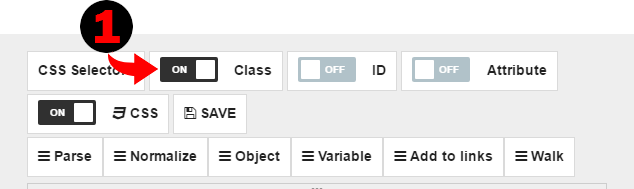
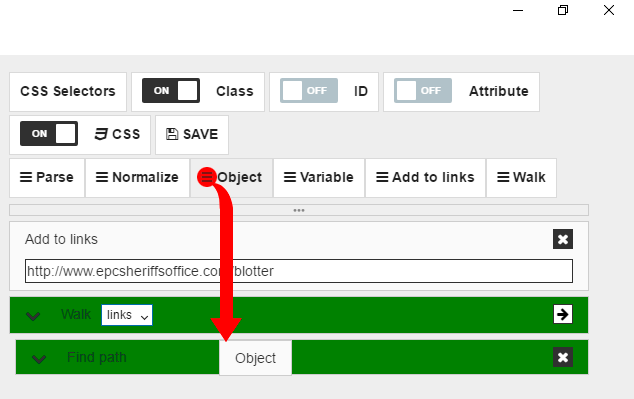
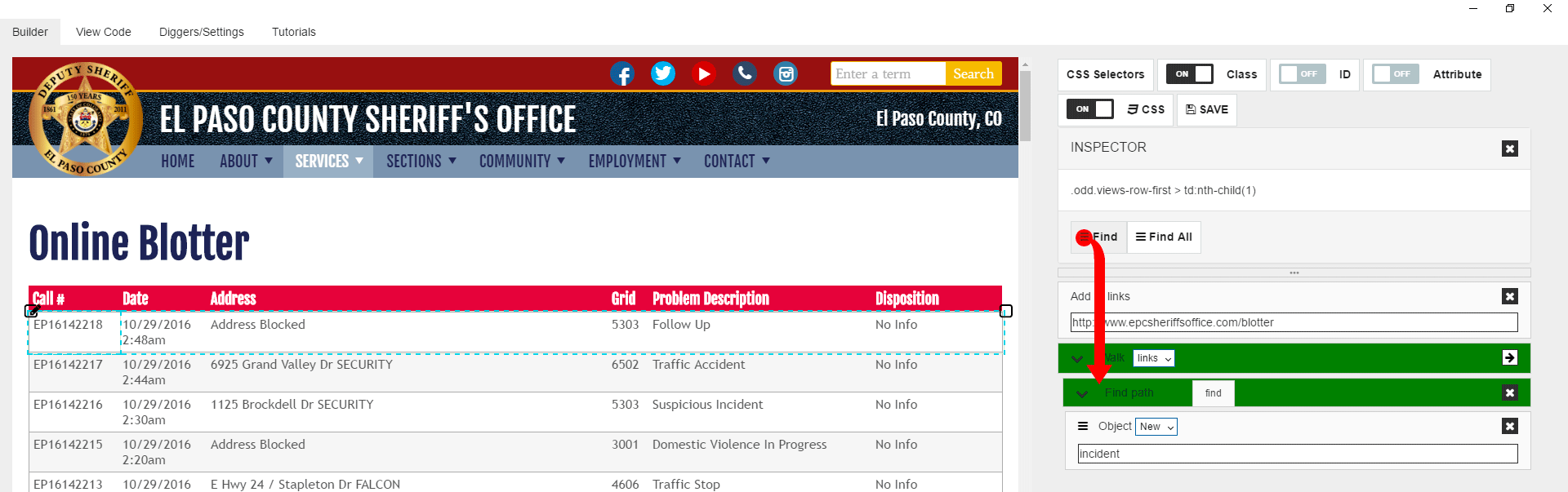
So we have a logic which loads URL and then proceed into each row, and we should create logic for data object population now. Each row in the table represents one data object we need. Each cell contains one or more fields for this data object. So first thing after we got into table row we should create the new data object. To do it we need to drag “Object” command to the “Find” block.
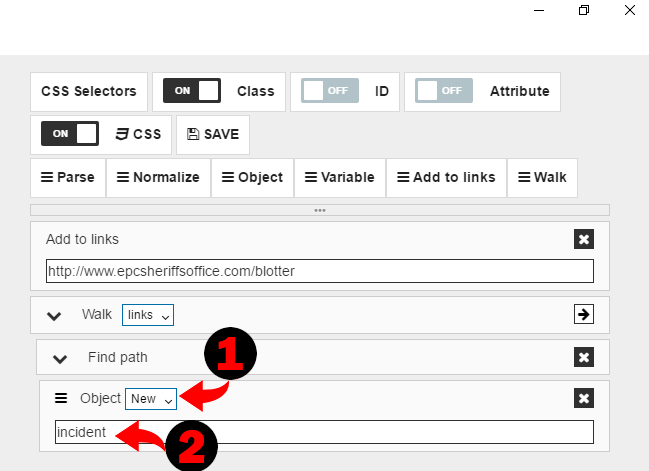
Then we need to select an option for “Object” command. Since we need to create a new object, we have to select “New” and then give the name for our object: “incident”.
We are going to walk into each cell now and parse data for our data fields. First, let’s click on the first cell inside the row we have selected. Now let’s pull “Find” command.
If you move the mouse over this new “Find” command, you see that first cell of each row is highlighted. It means we did it the right way. You can see that there is a “Parse” command in the “Find” block we just pulled. This command parses text information from the selected block. To preview data that is extracted with “Parse” you can click on the “Preview” icon. After it, you can preview extracted text for each selected block.
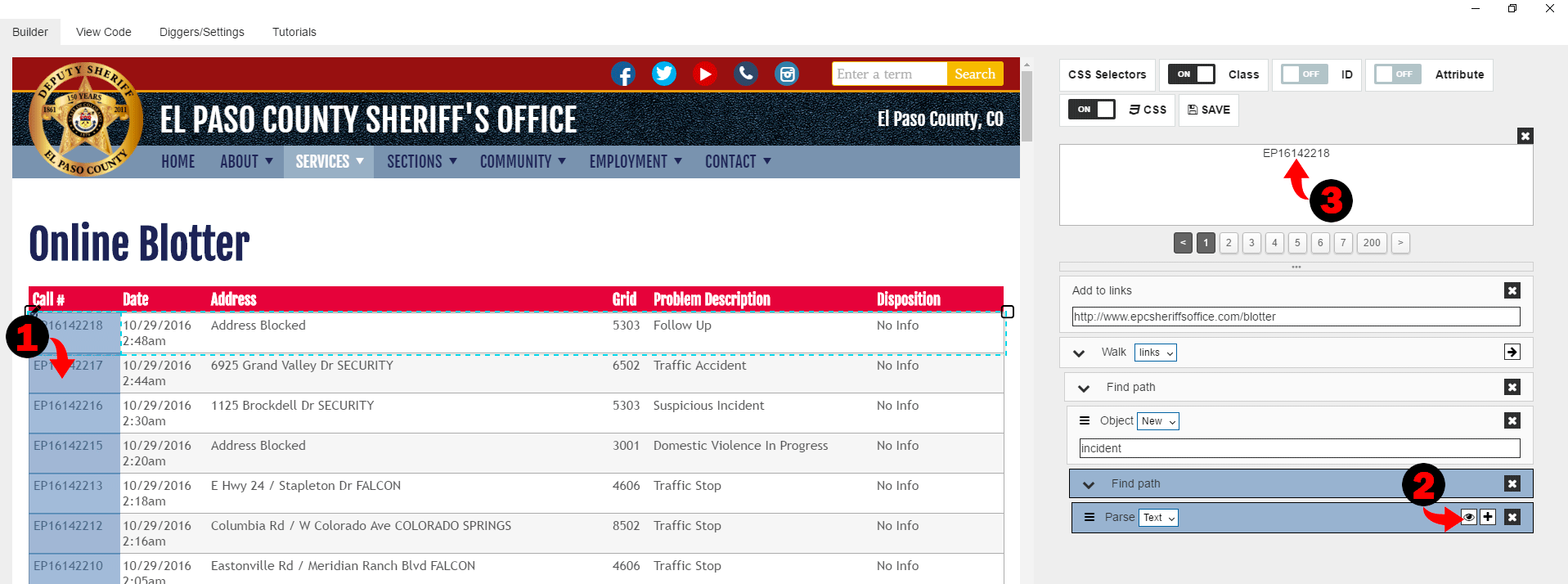
It seems like we extracted call number information correctly, lets then put it to the data structure field. We can do it by pulling “Object” command, then selecting “Fieldset” option and specifying field name and object name.
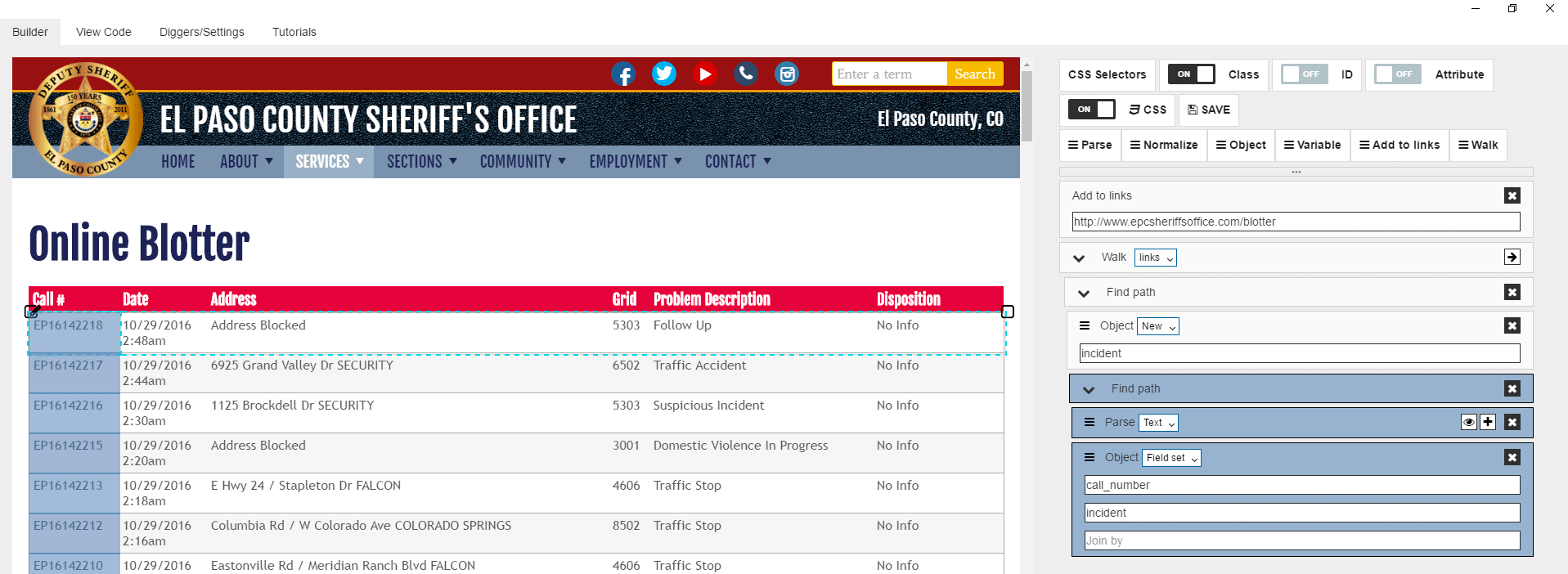
Then we can fold this find block by clicking on “Fold” icon.

Next cell has date and time data, let’s extract them separately. Click on the date.
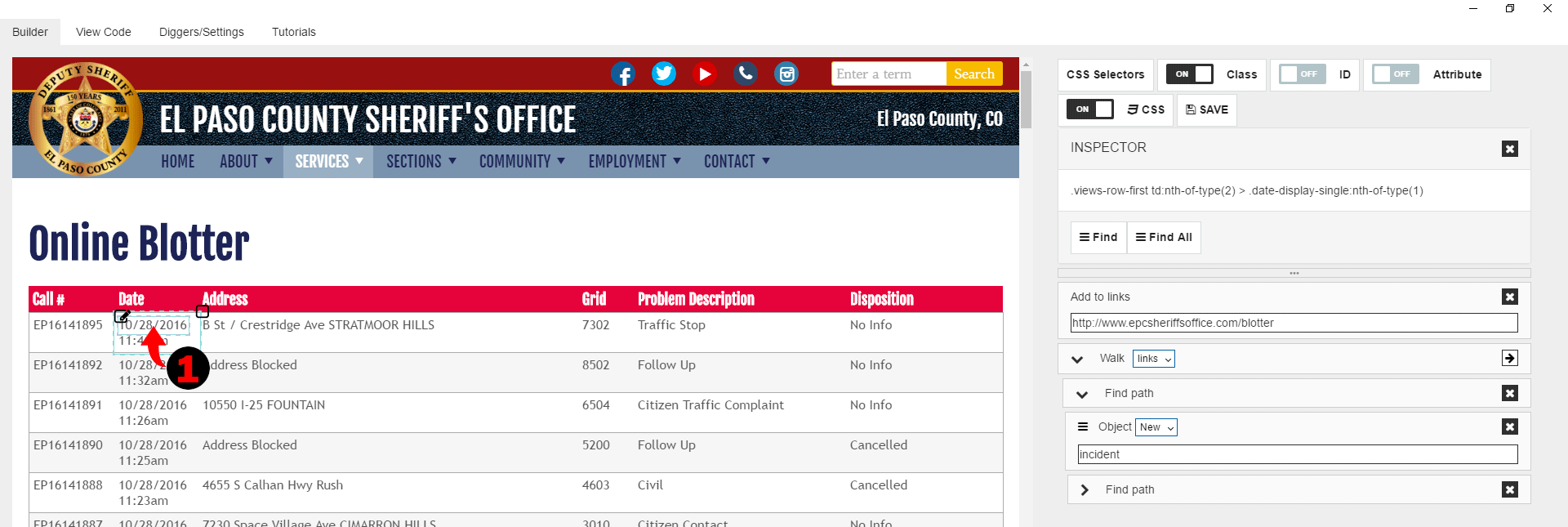
Then let’s do same we did for the first cell. When it’s done you should have something like:
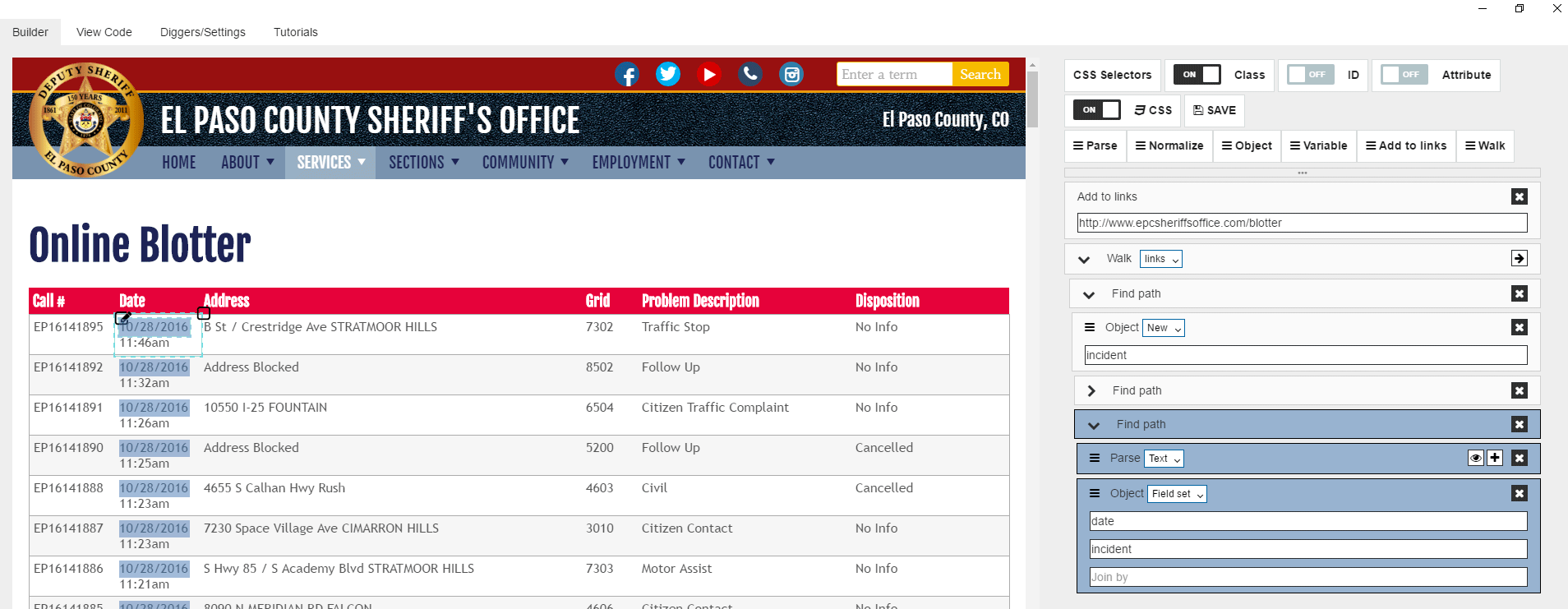
After it lets do the same for time and other cells in the row.
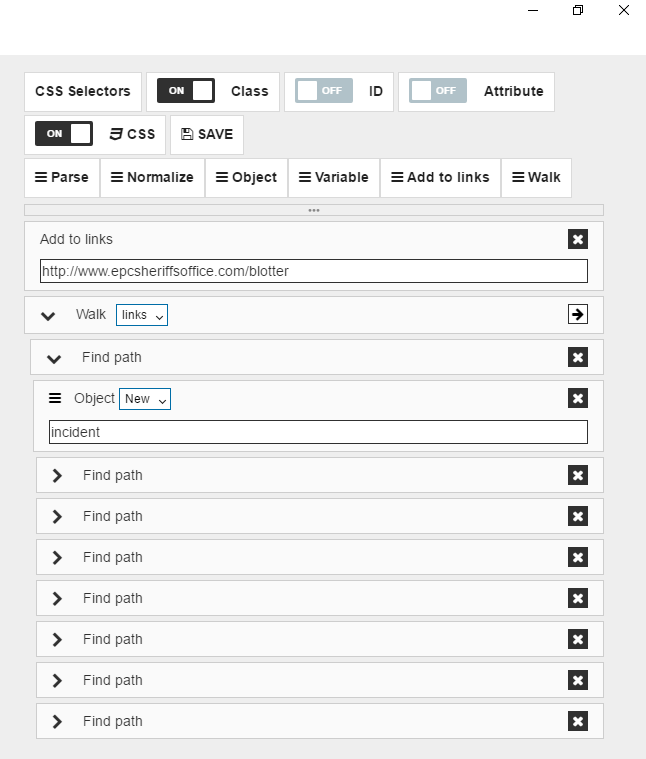
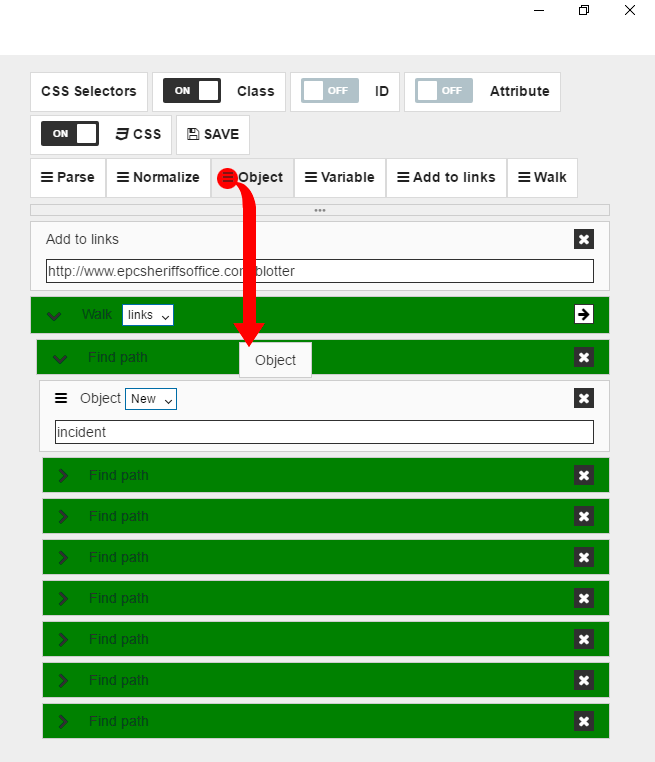
Finally we need to save our data object by dragging “Object” command,
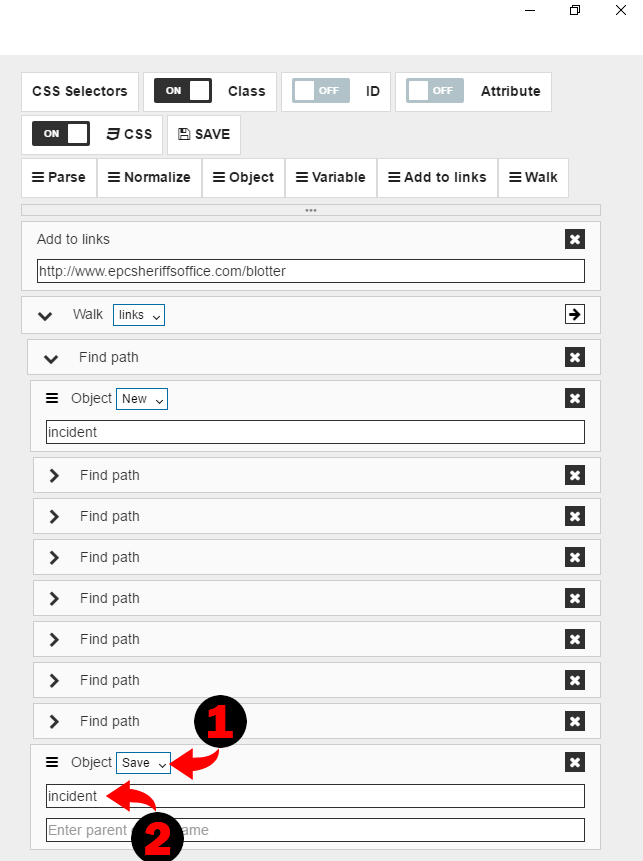
selecting “Save” option and specifying object name “incident”.
So we now have our main logic block done, if we’d run it right away, it will push URL to the links poll, then start iterate over this pool, so the first thing it does – walk to the first link in the pool. Then we have “Find” command which finds all table rows and iterates over them. Digger walks into each row and create new data object name “incident”, walk into each cell, parse data and save it to the specific field inside our data object. Then the object is saved to the DB. We should get a bunch of records in our database, but there are only rows from this particular page. What do we need to do to get data from all pages? There is paginator on the page, and it has “Next” link.
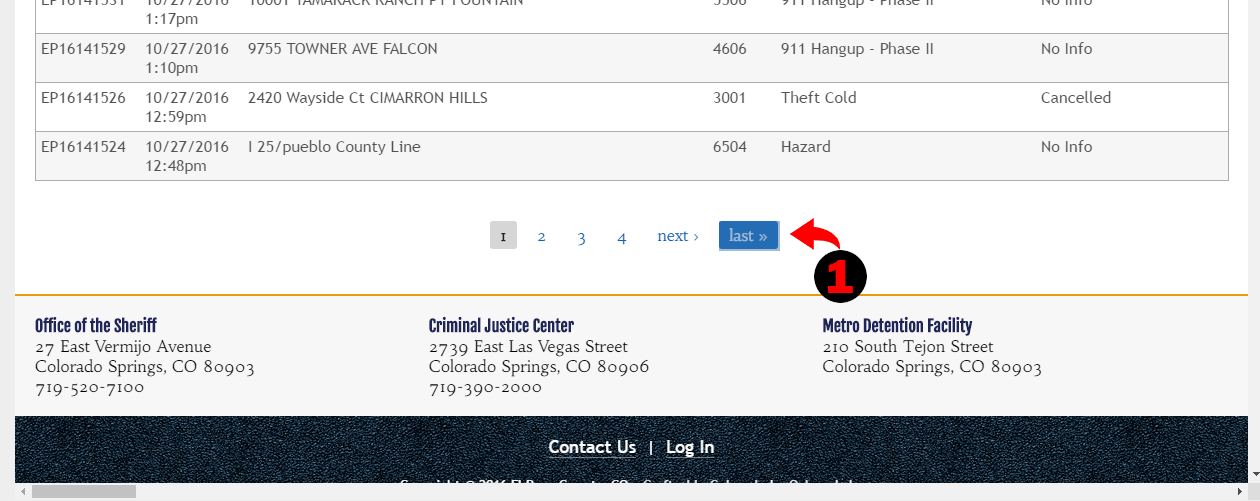
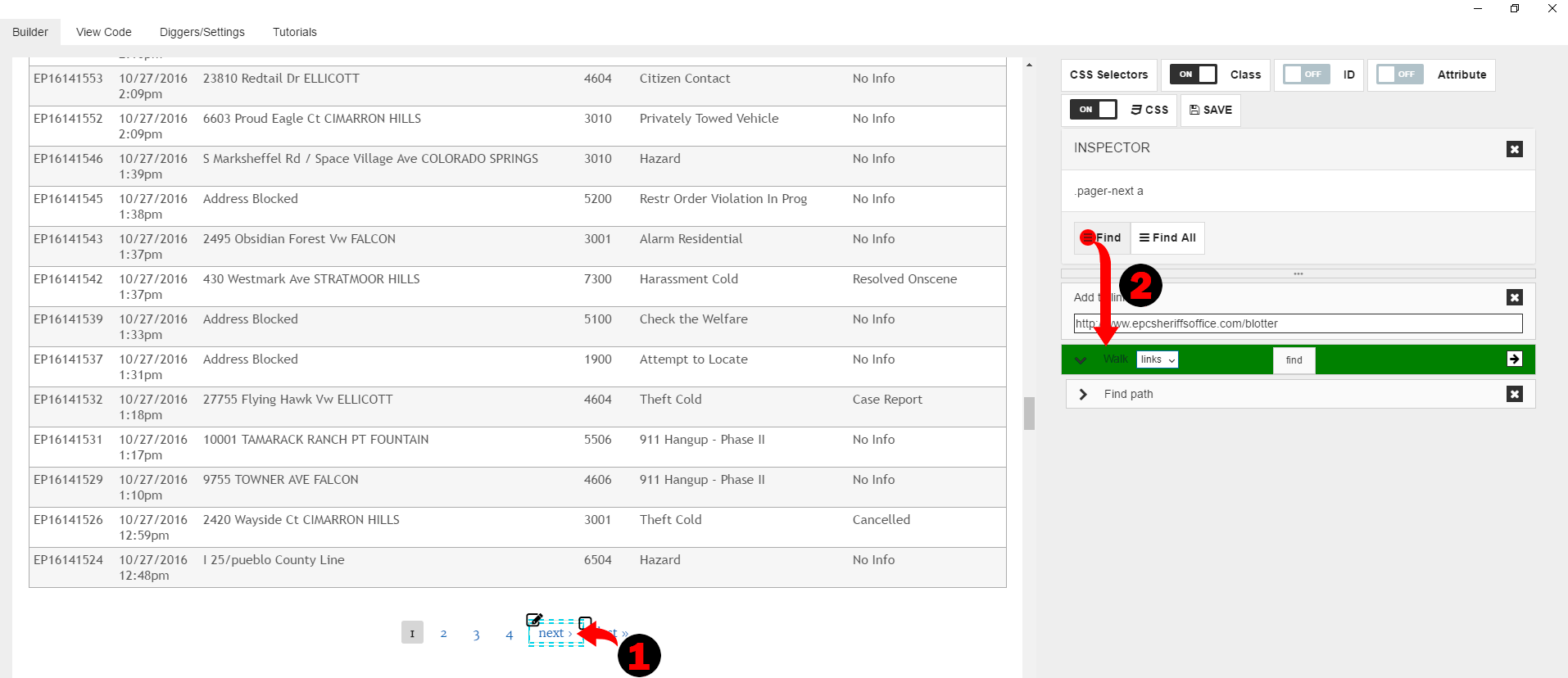
The easiest way to have digger to jump to the next page is to get next page link and push it to the links pool. So let’s click on the “Next” link and then drag “Find” command.
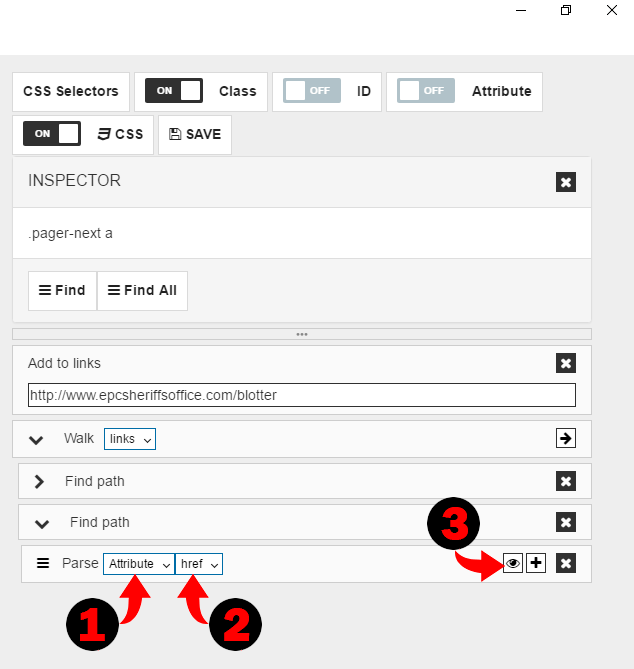
Parse command by default extracts text from selected block, and we need to extract link (or href attribute). So we need to select “Attribute” and attribute “href”. To ensure you selected it properly, you can use “Preview” function.
Finally, you need to pull “Add to links” command to push parsed URL to the pool.
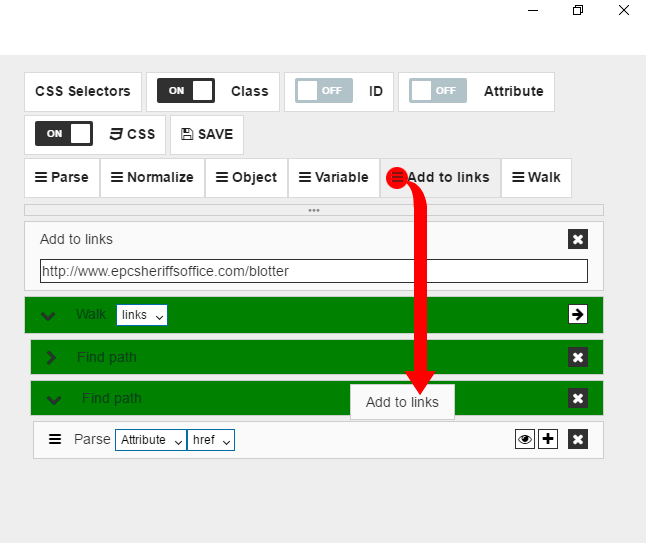
So now, after digger gets all data from the page, it checks for next page link, and if it exists, digger gets URL, push it to the pool and then walk to this URL. This way we get data from all pages.
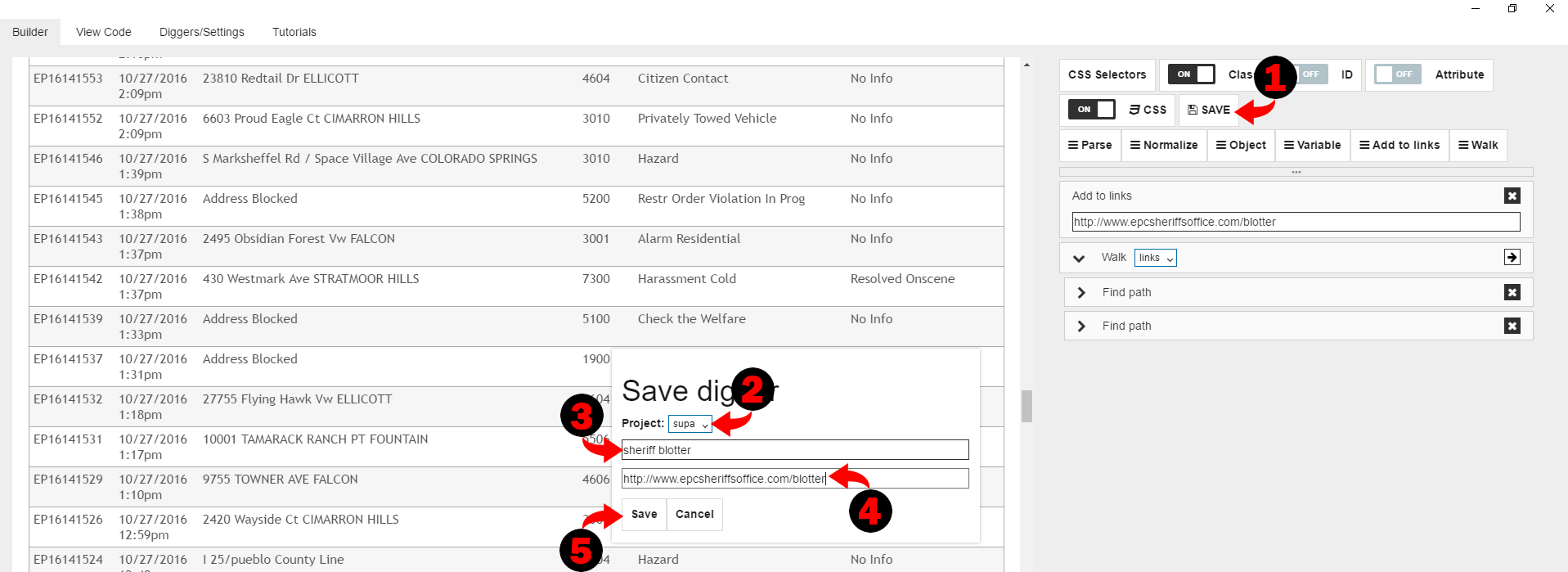
Since we are done, we can click on “Save” button to save our digger to the Diggernaut account. Select project, give a name for digger and URL of the website you are scraping. Then click on the “Save” button.
If all went well, you should see “Success” message.
That’s it, now you can log in to your Diggernaut account, find digger you created and run it, then go to data and download file with data. Configuration file for digger can be downloaded here.
