
We decided to do this small test to find out what is more efficient (speed, CPU and RAM usage wise) programming language for web scraping purposes. We wrote all scraping scripts in the same manner, and we ran it in a single thread. Each scraper we ran for 10 minutes on the same machine, almost at the same time. We ran it on: Linux Ubuntu 14.04 (under Virtual Box), 1 CPU Core, 4Gb RAM.
We compared following programming languages (frameworks): Golang + Diggernaut meta-language, Perl, PHP5, Python 2.7, Python + Scrapy, Ruby. As a target we used U.S. Department of Health & Human Services website.
Let’s look at the speed chart.
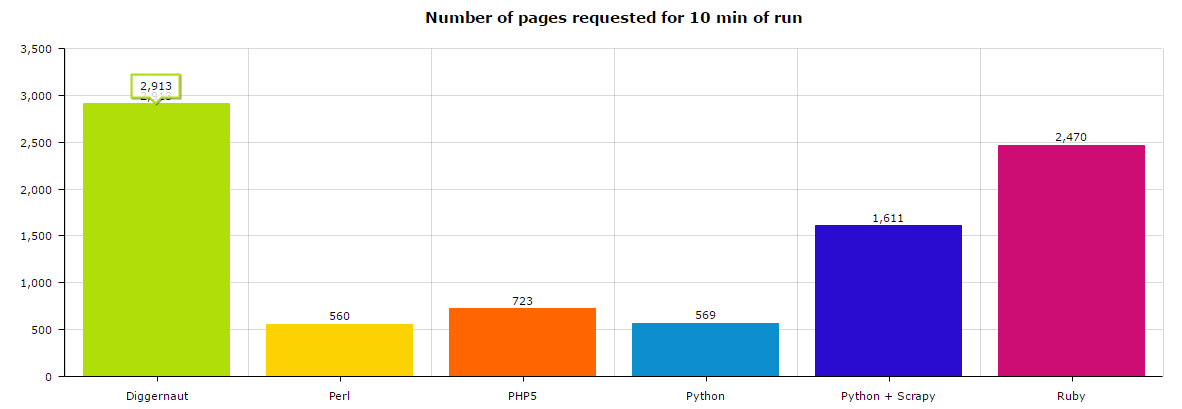
As you can see there are 3 leaders: Golang + Diggernaut was able to fetch almost 3K pages, Ruby – approx 2.5K and Python + Scrapy – approx 1.5K. Other languages are slow.
However, if we look at the CPU usage chart, we can see a bit different picture.
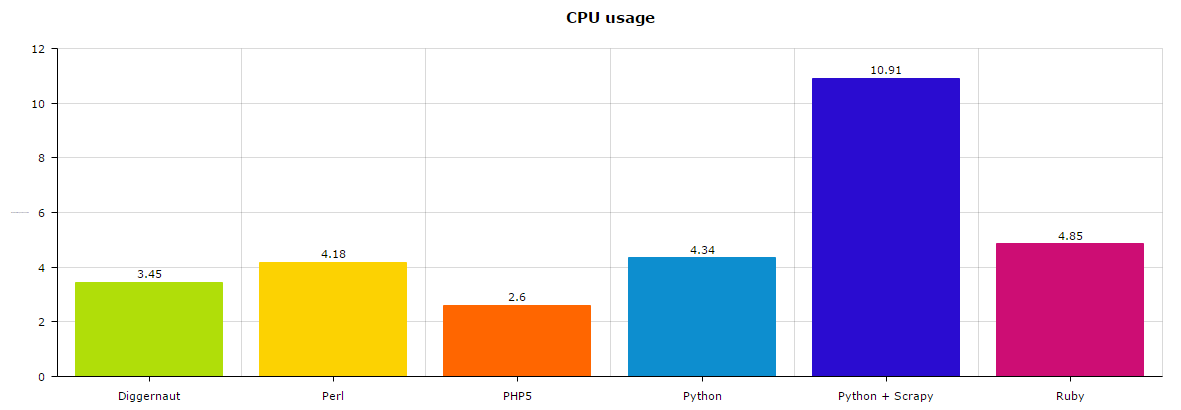
First place here goes to PHP5 which used just 2.5% of CPU, then Golang +Diggernaut with 3.5% and third is Perl with approx 4%. Other languages are also close by, except Python + Scrapy – 11% is a way too much we think.
And last parameter we measured is RAM usage:
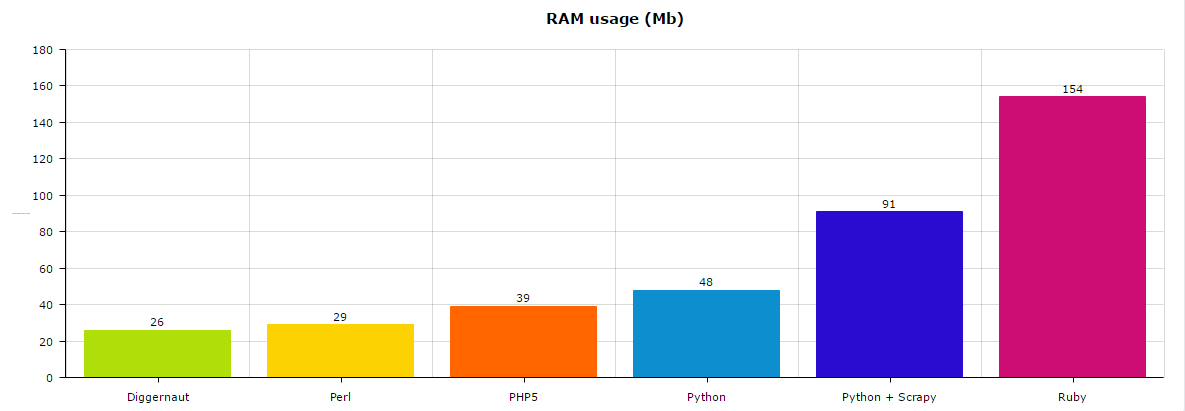
The winner here is Golang + Diggernaut with 26Mb, then Perl with 29Mb, and PHP5 with 39Mb. Ruby here is an outsider with 154Mb of RAM usage.
So to summarize measures we score each language using 100-points score system. Each measure goes separately (best result gets 100 points, worst gets 0 points) and then we use average.
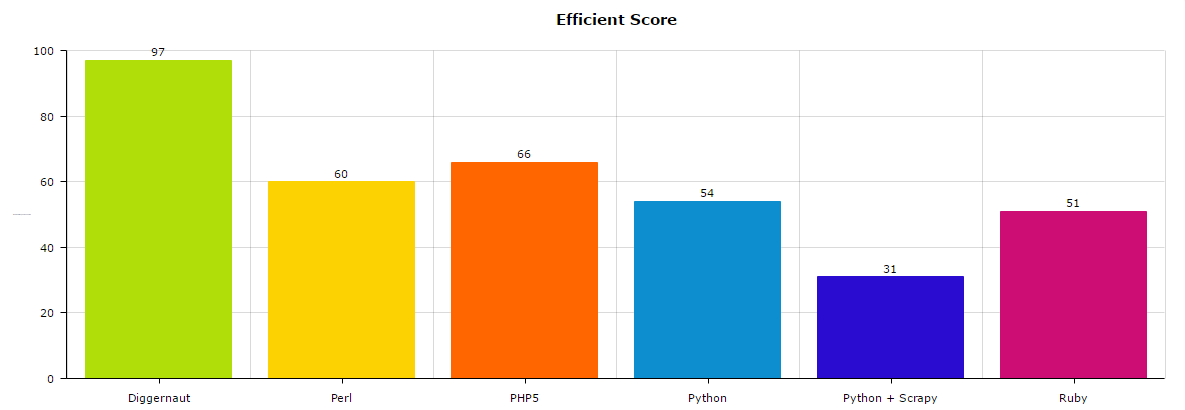
Golang is a clear winner in this run.
We decided to attach files we used for test, so you may try and ensure: scripts

You should have tested nodejs and Java to be fair. Async is a key in that kind of task.
Async may be not so fair in this comparison. But we planned make test for it. If you can help us for making scripts – you are welcome. But in multi-threading test we will use own site as source as we don’t want to abuse other sites with hammering.
Let’s see the code.
Without knowing what you’re doing, it’s impossible to believe your conclusions.
Scripts attached to the end of the post.
I had a look at the perl script (since I’m a perl dev) and I saw that you guys loaded the ‘Data::Dumper’ module, probably for debugging purposed, but then I haven’t seen and use of it’s Dumper function. So since Data::Dumper is seen as a heavy module, removing it (line no 8) from your script will bring the startup time and memory usage a bit down in favor of perl. Also wich version of perl are you using? For example the lates ones (5.16 and above) are noticeably faster than 5.8.8. Cheers
Well , you could make your Scrapy scraper go faster if you didn’t reduce the number of CONCURRENT_REQUESTS to 10 . I mean, you might fool dumb people or your clients, but just by looking at the settings.py I can see you reduced the CONCURRENT_REQUESTS to 10 instead of the default 16. I bet if you increased it to 32 , you would go twice as fast as your supposed diggernaut scraper.
Erik, test was done in single thread, meaning one request at time. But even if we would compare multi-threading situation, I really doubt that python will be faster than golang when you are threading, we had one case before where python wasnt able to handle task (with a lot of threads) and we solved it with golang.
Thats not how non-blocking i/o works. multi-threading has absolutely ZERO to do with request concurrency
It`s not true. Multi-threading allow you to run more concurrent request on other cores. Our engine works synchronously, without using event-loop, gorotines or other patterns of concurrent processing. But we had a client in whose requirements there were 1500 requests for their processing and writing to the database in less than 10 seconds. Python could not cope with this, unlike go.
Nice article.
I was shocked about python results really!!